Last week, the 10th Conference of the Open Access Publishing Association was held in Vienna. Much was covered over the two and a half days. A decade in, this conference considered the state of the open access (OA) movement, discussed different approaches to OA, considered inequity and the infrastructure required to meet this need and argued about language. Apologies – this is a long blog.
Fracturing of the ‘OA movement’?
In an early discussion, Paul Peters, OASPA President and CEO of Hindawi noted that similarly to movements like organic food or veganism, the OA ‘movement’ is not united in purpose. When what appear to be ‘fringe’ groups begin, it is easy to assume that all involved take a similar perspective. But the reasons for people’s involvement and the end point they are aiming for can be vastly different. Paul noted that this can be an issue for OASPA because there is not necessarily one goal for all the members. He posed the question about what this might mean for the organisation.
It also raises questions about approaches to ‘solving’ OA issues. Many different approaches were discussed at the event.
Unbundling
The concept of ‘unbundling’ the costs associated with publishing and offering these to people to engage with on an as needs basis was raised several times. This points to the concept put forward last year by Toby Green of the OECD. It also triggered a Twitter conversation about the analogy of the airline industry (and how poorly they treat their customers).
If the scholarly journal were unbundled, different players could deliver the functions. Kathleen Shearer, Executive Director of COAR noted that not all functions of scholarly publishing need to take place on the same platform. She suggested next generation repositories as one of the options.
Jean-Claude Guedon provided several memorable quotes from the event, with the most pertinent being “We don’t need a ‘Version of Record’. We need a ‘record of versions’”. Kirsten Ratan, of Coko Foundation agreed in her talk on infrastructure, stating “we publish like its 1999”. The Version of Record is the one that matters and it is static in time. But it is not 1999, she noted, and we need to consider the full body of work in its entirety.
After all, it was observed elsewhere at the conference, nothing radical has changed in the format of publications over the past 25 years. We are simply not using the potential the internet offers. Kathleen quoted Einstein stating “You cannot solve a problem from the same consciousness that created it. You must learn to see the world anew”.
New subscribing models
Wilma van Wezenbeek, from TU Delft and Programme Manager, Open Access, VSNU discussed the approach to negotiations taken in The Netherlands. They are arguing that when comparing how much is spent per article under the toll system and what it would cost to have everything published OA, that enough money exists in the system. VSNU are being pragmatic, focusing on big publishers and going for gold OA (to avoid the duplication of journals). She also noted how important it is for libraries to have presidents of the University at the negotiation table. Her parting advice on negotiations was to hold your nerve, stay true to the principles and don’t waiver.
This approach does not include smaller publishers and completely ignores fully gold publishers, an observation that was made a few times in the conference. An alternative approach, argued Kamran Naim, Director of Partnerships & Initiatives at Annual Reviews, was collective action. In his talk ‘Transitioning Subscriptions to OA Funding: How libraries can Subscribe to Open’ he asked what is required to flip the subscription cost to manage OA publication (instead of APCs). The challenge with this idea is it requires people to continue subscribing even when material is OA and they don’t have to. Another problem is the idea of ‘subscribing’ to OA material can become a procurement challenge. This cost can be classified as a ‘donation’ which is not allowed by some library budgets. So the suggestion is that subscribing libraries will be offered to subscribe to select journals and receive 5% off the subscription cost. The plan is to roll out the project to libraries in 2019 for 2020 models.
Study – downloading habits when material is OA
A very interesting study was presented by Salvatore Mele and Alexander Kohls from CERN and SCOAP3. Entitled ‘Preprints vs traditional journals vs Open Access journals – What do scientists download?’ the study compared downloads of the same scientific artefact as a preprint on arXiv and as a published article on a (flipped) journal platform.
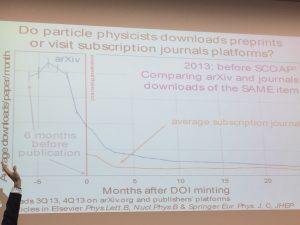 Their findings, which came from arXiv, Elsevier and SpringerNature’s statistics, showed that there is a significant use of the version in arXiv during the first six months (when the only version of the work is available in arXiv) which drops off dramatically after the work is published (a point identified as when the DOI is minted).
Their findings, which came from arXiv, Elsevier and SpringerNature’s statistics, showed that there is a significant use of the version in arXiv during the first six months (when the only version of the work is available in arXiv) which drops off dramatically after the work is published (a point identified as when the DOI is minted).
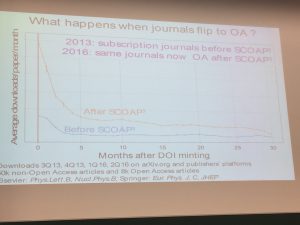 They also compared downloads from 2013 – before the journals flipped to gold under the SCOAP3 arrangement with those from 2016 when the journals were open access. The pattern over time was similar, but accesses in 2016 were higher overall over time, but dramatically higher in the first three months after the DOI was minted.
They also compared downloads from 2013 – before the journals flipped to gold under the SCOAP3 arrangement with those from 2016 when the journals were open access. The pattern over time was similar, but accesses in 2016 were higher overall over time, but dramatically higher in the first three months after the DOI was minted.
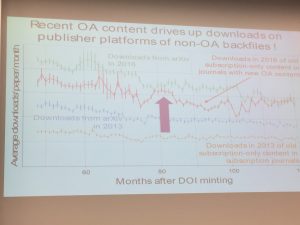 The final slide demonstrated that having recent open access content was also driving up downloads of older works in the non-open access backfiles from the publisher platforms.
The final slide demonstrated that having recent open access content was also driving up downloads of older works in the non-open access backfiles from the publisher platforms.
This work is not published “because we have day jobs”. I have included my poor images of the slides in this blog and will link to the slides when they are made available.
Nostalgia
Being the 10th OASPA conference there was some reminiscing throughout the presentations. In a keynote reflection on the Open Access movement, Rebecca Kenniston from KN Consultants noted several myths about OA publishing that existed 10 years ago that still persist. Rebecca discussed “library wishful thinking” when it came to OA. This has included thinking OA would solve the serials crisis, that practice would change ‘if only the academic community were aware’, that institutional repositories and mandates would solve OA. (Certainly one of my own observations over the 16 or so years I have been involved in OA is there is always a palpable sense of glee at OA events when ‘real’ researchers bother to turn up.)
David Prosser, Executive Director of Research Libraries UK was outed as the architect of the ‘hybrid’ option, which he articulated in his 2003 paper “From here to there: a proposed mechanism for transforming journals from closed to open access“. David defended himself by noting that the whole concept did not work because it was proposed with an assumption about the “sincerity of the industry to engage”.
This made me consider the presentation I gave to another 10th anniversary conference this year – Repository Fringe at Edinburgh. In 1990 Steven Harnad wrote about ‘Scholarly Skywriting’ and described the obstacles to the ‘revolution’ as including ‘old ways of thinking about scientific communication and publication’, ‘the current intellectual level of discussion on electronic networks is anything but inspiring’, ‘plagiarism’, ‘copyright’ and ‘academic credit and advancement’ amongst others. Little appears to have changed in the past 28 years.
The more perceptive readers will note how long ago these dates are. This OA palaver has been going on for decades. And it seems even longer because, as Guido Blechl from the University of Vienna noted, “open access time is shorter than normal time because it moves so fast”.
But none of this wishful thinking has come to fruition. Rebecca asked “what shift do we need in our thinking?” Well in many ways that shift has landed in the form of Plan S. See the related blog for the discussions about Plan S that happened at the conference.
Language matters
Rebecca also mentioned “our own special language”, which is, she observed, a barrier to entry to the discussion. Indeed language issues came up often during the few days of the conference.
There were a few references to the problems with the terms ‘green’ and ‘gold’, and specifically gold. This has long been a personal bugbear of mine because of the nonsensical nature of the labels, and the associations of ‘the best’ and ‘expensive’ with gold. There has been a co-opting of the term ‘gold’ by the commercial publishing sector to mean ‘pay to publish’. Of course all *hybrid* journals charge an APC, and more articles are published where an APC has been paid than not, which is possibly why the campaign has been successful – see the Twitter discussion here. But it is inaccurate. In truth, ‘gold’ means the work is open access from the point of publication. More fully gold open access journals do not charge an APC than do.
There was also concern raised about the term ‘Open Science’ which, while in Europe is an inclusive term to cover all types of research, is not perceived this way in other parts of the world. There was strong support amongst the group for using the term ‘Open Scholarship’ as an alternative. This also brought up a discussion about using the term ‘publication’ rather than the more inclusive research ‘outputs’ or ‘works’, which encompass publishing options beyond the concept of a book or a journal.
Inequity
“Inclusivity is not optional! We need a global (information/publishing) system!” was the rallying cry of Kathleen Shearer in her talk.
For many in the OA space, equity of access to research outputs lies at the centre of what the end goal is. It is clear that knowledge published by academic journals is inaccessible to the majority of researchers in low- and middle-income countries. But if we move to a fully gold environment, with the potential to increase the cost of author participation in the publishing environment, then we might have simply reversed the problem. Instead of not being able to read research, academics in the Global South will be excluded from participating in the academic discussion.
There was a discussion about the change in global publishing output since 2007, which reflects a big increase in output from China and Brazil, but otherwise shows that output is uneven and not inclusive.
One possible solution to this issue would be for open access publishers to make it clearer to authors that they offer waivers for authors who are unable to pay the APC. There was discussion about the question ‘what form should OA publishing take in Eastern and Southern Europe?’. The answer was that it should be inexpensive and use infrastructure that is publicly owned and cannot be sold.
Infrastructure
Ahhhh infrastructure. We are working within a fast consolidating environment. Elsevier continues to buy up companies to ensure it has representation across all aspects of the scholarly ecosystem and Digital Science is developing and acquiring new services to a similar end. See ‘Virtual Suites of tools/platforms supported by the same funder’ and ‘Vertical integration resulting from Elsevier’s acquisitions’. These are obvious examples but Clarivate Analytics has recently acquired Publons and ProQuest has absorbed Ex Libris which has in turn bought Research Research and has plans to create Esploro – a cloud-based research services platform, so this is prevalent across the sector.
This raises some serious concerns for the concept of ‘openness’. In his excellent round up, Geoff Bilder, Director of Strategic Initiatives at Crossref, commented that we are looking in the rear view mirror at things that have already happened and we are not noticing what is in front of us. While we might end up in a situation where publications are open access, these are not representative of the discussions that occurred to allow the authors to come to those conclusions. The REAL communication happens in coffee shops and online discussions. If these conversations are using proprietary systems (such as Slack, for example), then these conversations are hidden from us.
Who owns the information about what is being researched and the data behind it when the scholarly infrastructure is held within a commercial ecosystem? Is there an opportunity to reimagine? asked Kirsten Ratan, referencing SPARC’s action plan on ‘Securing community controlled infrastructure’. “In scholarly communication,” she summarised, “we have accepted the limitations of the infrastructure with a learned helplessness. It‘s time that these days are over.”
There are multiple projects currently in place around the world to collectively manage and support infrastructure. Kathleen Shearer described several projects:
- Consortia negotiations such as OA2020 and SCOAP3
- The Global Sustainability Coalition for Open Science Services (SCOSS) is an international group of leading academic and advocacy organisations that came together in 2016 to help secure the vital infrastructure underpinning Open Access and Open Science. SPARC Europe is a founding member.
- The 5% commitment is a call that “Every academic library should commit to contribute 2.5% of its total budget to support the common infrastructure needed to create the open scholarly commons”. This is primarily a US and Canadian discussion.
- OA membership models
- APC funds
There are actually a couple of other projects not mentioned at COASP 2018. In 2017, several major funding organisations met and came to a strong consensus that core data resources for life sciences should be supported through a coordinated international effort to both ensure long term sustainability and appropriately align funding with scientific impact. The ELIXIR Core Data Resources project is identifying resources defined as a set of European data resources that are of fundamental importance to the wider life-science community and the long-term preservation of biological data.
OA Monographs
The final day of the event looked at OA monographs. Having come from a British Academy event on OA monographs the week before (see the Twitter discussion), this debate is fairly top of mind at the moment for me.
Sven Fund, who is both the Managing Director of Knowledge Unlatched and of fullstopp which is running a consultation on OA monographs for Universities UK, spoke about the OA monograph market. He noted that books are important, and not just because “people like to decorate their living rooms with them”. But he suggested that rather than just adding a few hyperlinks, we should be using the technology available to us with books. It has been the smaller publishers who have been innovating, large publishers have not been involved, which has limited the level of interest.
The OA book market is still small, with only 12,794 books and chapters listed in the Directory of OA Books (DOAB) compared to over 3 million articles listed in the Directory of OA Journals (DOAJ). But growth in OA books is still strong even though the OA journal market matures. Libraries are the bottleneck, Sven argued, because they need to change the funding model significantly. There has been 10-15 years of discussion and now is the time to act. Libraries need to make a significant commitment that X% goes into open access.
There are also problems with demonstrating proof of impact of the OA book. Sven argued we need transparency and simplicity in the market, and said that no-one is doing an analysis of which books should be OA or not based on impact and usage. This needs to happen.
Sven said that royalties are important to authors – not because of the money but because it shows how much the work has been read. For this reason he argued we need publishers to share their usage data for a specific OA titles with the author. As an aside, it seems extraordinary that publishers are not already doing this, and I asked Sven why they don’t. He replied that it seems that ‘data is the new gold’ and therefore they do not share the information. Download information about open books is often protected because of the risk a of providing information that gives their competitors a commercial advantage.
But Sven also noted there needs to be context in the numbers. Libraries in the past have done a simple analysis of cost per download without taking into consideration the differences in topics. Of course some areas cost more per download than others, he said. There is also the risk that if you share this data then you might have a situation where a £10,000 book only has a few downloads which ‘looks bad’.
The profit imperative
There were some tensions at the meeting about profits. A question that arose early in the first panel discussion was: “Should we be ashamed as commercial publishers for making money?”. One response was that if you don’t make money you are not a commercial publisher. But the same person noted the ‘anti commercial sentiment’ in these discussions indicate that something is wrong.
A secondary observation was that open access publishers are doing a good job “while the current incentive systems are in place”. This of course points to the academic reward system controlling the behaviour of all players in this game.
As is always the case at open meetings, the Journal Impact Factor was never far away, although Paul Peters noted that the JIF was partly responsible for the success of OA journals, PLOS ONE took off when it received an impact factor. It was noted in that discussion that OA journals obtaining and increasing their JIF is ‘not proof of success, it’s proof of adaptation’.
The final talk was from Geoff Bilder. One participant described his talk on Twitter as “the best part of the publishing conference, where Geoff Bilder tells us everything that we’re doing that’s wrong”. Geoff noted that throughout the conference people had used some terms fairly loosely, including ‘commercial’ and ‘for profit’. He noted that profit doesn’t necessarily mean taking money out of the system, often profit is channelled back into the business.
In the end
 In all it was an interesting and thought provoking conference. Possibly the most memorable part was the 12 flights of stairs between the lecture rooms and the breakout coffee and lunch space. This has been the first OA conference I have attended where participants improved their cardiovascular fitness as a side bonus to the event.
In all it was an interesting and thought provoking conference. Possibly the most memorable part was the 12 flights of stairs between the lecture rooms and the breakout coffee and lunch space. This has been the first OA conference I have attended where participants improved their cardiovascular fitness as a side bonus to the event.
The Twitter hashtag is #COASP10
Published 24 September 2018
Written by Dr Danny Kingsley

{kind=link}