The Office of Scholarly Communication, jointly with Open Research Systems (Digital Initiatives) and Research Information team have developed a new preprint deposit service for University of Cambridge researchers, which will be available on the week commencing11th March 2024.
Why offer a preprint service?
Although researchers are generally well-served by existing subject repositories/preprint servers, we have identified an unmet need for those:
Who have no suitable subject repository/preprint server, or
Whose subject repositories/preprint server may be unable to offer long-term preservation, or
Who wish to use the University’s repository instead of existing subject repositories/preprint servers.
Why offer a preprint service now?
Following recent upgrades to both the University’s repository Apollo and Elements (the system that the University uses to hold and manage data on research activity), we are now in a position where we can offer a preprint deposit service.
What can be deposited?
Cambridge University researchers can deposit new (unpublished) preprints that have not been submitted to an external subject repository/preprint server.
Researchers can also deposit published preprints if they have concerns about its long-term preservation.
Can subsequent versions of a preprint be deposited?
New versions of a preprint can be added to an existing preprint record.
What happens once the preprint has been accepted for publication?
Researchers are asked to deposit the accepted manuscript as usual, via Elements. The Open Access Team will link the preprint record and accepted manuscript record in Apollo. The preprint and the accepted manuscript need to be separate records to ensure that the first deposit date of the accepted manuscript is not obscured, which is important for REF compliance purposes.
This year we have continued, as always, to provide support and services for researchers to help with their research data management and open data practices. So far in 2020, we have approved more than 230 datasets into our institutional repository, Apollo. This includes Apollo’s 2000th dataset on the impact of health warning labels on snack selection, which represents a shining example of reproducible research, involving the full gamut: preregistration, and sharing of consent forms, code, protocols, data. There are other studies that have sparked media interest for which the data are also openly available in Apollo, such as the data supporting research that reports the development of a wireless device that can convert sunlight, carbon dioxide and water into a carbon-neutral fuel. Or, data supporting a study that has used computational modelling to explain why blues and greens are the brightest colours in nature. Also, and in the year of COVID, a dataset was published in April on the ability of common fabrics to filter ultrafine particles, associated with an article in BMJ Open. Sharing data associated with publications is critical for the integrity of many disciplines and best practice in the majority of studies, but there is also an important responsibility of science communication in particular to bring research datasets to the forefront. This point was discussed eloquently this summer in a guest blog post in Unlocking Research by Itamar Shatz, a researcher and Cambridge Data Champion. Making datasets open permits their reuse, and if you have wondered how research data is reused and then read this comprehensive data sharing and reuse case study written by the Research Data team’s Dominic Dixon. This centres on the use and value of the Mammographic Image Society database, published in Apollo five years ago.
This year has seen the necessary move from our usual face-to-face Research Data Management (RDM) training to provision of training online. This has led us to produce an online training session in RDM, covering topics such as data organisation, storage, back up and sharing, as well as data management plans. This forms one component of a broader Research Skills Guide – an online course for Cambridge researchers on publishing, managing data, finding and disseminating research – developed by Dr Bea Gini, the OSC’s training coordinator. We have also contributed to a ‘Managing your study resources’ CamGuide for Master’s students, providing guidance on how to work reproducibly. In collaboration with several University stakeholders we released last month new guidance on the use of electronic research notebooks (ERNs), providing information on the features of ERNs and guidance to help researchers select one that is suitable.
At the start of this year we invited members of the University to apply to become Data Champions, joining the pre-existing community of 72 Data Champions. The 2020 call was very successful, with us welcoming 56 new Data Champions to the programme. The community has expanded this year, not only in terms of numbers of volunteers but also in terms of disciplinary focus, where there are now Data Champions in several areas of the arts, humanities and social sciences in particular where there were none previously. During this year, we have held forums in person and then online, covering themes such as how to curate manual research records, ideas for RDM guidance materials, data management in the time of coronavirus, and data practices in the arts and humanities and how these can be best supported. We look forward to further supporting and advocating the fantastic work of the Cambridge Data Champions in the months and years to come.
At the heart of the University of Cambridge’s Open
Access Policy is the commitment “to disseminating its research and scholarship
as widely as possible to contribute to society”.
Behind this aim is the benefit to researchers worldwide, as the OA2020 vision has it, to “gain immediate, free and unrestricted access to all of the latest, peer-reviewed research”. It’s some irony indeed that the growth of the availability of research as open access does not automatically result, without further community investment, in a corresponding improvement in discoverability.
Key stakeholders met at the British Library to discuss the issue at the end of 2018 and produced an Open Access Discovery Roadmap , to identify areas of work in this space and encourage collaboration in the scholarly communications community.[1] A major theme included the dependence on reliable article licence metadata, but the main message was finding the open infrastructure/interoperability solutions for long-term sustainability “ensuring that the content remains accessible for future generations”.
New web pages on Open Access discovery
Recognizing where we are now, and responding to the present, (probably) partial awareness of the insufficiencies in the OA discovery landscape, Cambridge University Library has added pages to its e-resources website to highlight OA discovery tools and important websites indexing OA content. The motivations for highlighting the options for OA discovery on the new pages is described in this blog post. Our main aim is to bring to light search and discovery of OA as a live topic and prevent it “languishing in undiscoverable places rather than being in plain sight for everyone to find.”[2]
Recently, data from Unpaywall for July 2019 has been used to forecast for growth in availability of articles published as OA by 2025, predicting on the basis of current trends, but conservatively – without even taking full account of the impact of Plan S, for example. This forecast for 2025 predicts
44% of all journal articles will be available as OA
Unpaywall’s estimate for availability OA right now is 31%. A third (growing soon to a half) is a significant proportion for anyone’s money, and wanting to signal the shift we have used that statistic as our headline on the page summarizing the most well-known and commonly-used Open Access browser plugins.
Screenshot of Open Access browser plugins webpage
We want the Cambridge researcher to know about these plugins and to be using them, and aim to give minimal but salient information for a selection of one, or several, to be made. Our recommendation is for the Lean Library extension “Library Access” but we have been in touch with Kopernio and QxMD and ensured that members of the University registering to use these plugins will also pick up the connection to our proxy server for seamless off campus access to subscription content where it exists, before the plugin offers an alternative OA version.
Once installed in the user’s browser, the plugin will use the DOI and/or a combination of article metadata elements to search the plugin’s database and multiple other data sources. A discreet, clickable pop-up icon will become live (change colour), on finding an OA article and will deliver the link or the PDF direct to the user’s desktop. Most plugins are compatible with most browsers, Lean’s Library Access adding compatibility with Safari last month.
Each plugin has a different history of development and certain features that distinguish it from others, and we’ve attempted to bring these out on the page. For example noting Unpaywall’s trustworthiness in the library space thanks to its exclusion of ResearchGate and Academia.edu; its harvesting and showing of licence metadata; and its reach with integrating search of its data via library discovery systems. Features we think are relevant for potential users looking for a quick overview of what’s out there are also mentioned, such as Kopernio’s Dropbox file storage benefits and integration with Web of Science and QxMD’s special applications for medical researchers and professionals.
In an adjacent page, Search Open Access, there is coverage of search engines focused on discovering OA content (Google Scholar; 1findr; Dimensions; CORE), a range of sites indexing OA content in different disciplines, both publisher- and community-based, and a selection of repositories and preprint servers, including OpenDOAR.
Screenshot of Search Open Access webpage
We hope the site design, based on the very cool Judge Business School Toolbox pages, gets across the basics about the OA plugins available and encourages their take-up. The plugins will definitely bring to the researcher OA alternative versions when subscription access puts the article behind a paywall and, regardless, will expose OA articles in search results that will otherwise be hard to find. The pages’ positioning top-left on the e-resources site is deliberately intended to grab attention, at least for reading left-to-right. It is interesting to see the approach other Universities have taken, using the LibGuide format for example at Queen’s University Belfast and at the University of Southampton.
Experiences with Lean Library’s Library Access plugin
Cambridge has had just over a year of experience implementing Lean Library’s Library Access plugin, and it’s been positive. The impetus for the institutional subscription to this product was as much to take action on the problem for the searcher of landing on publisher websites and struggling with Shibboleth federated sign-on. This problem is well documented (“spending hours of time to retrieve a minimal number of sources”) and most recently is being addressed by the RA21 project.[4] Equally though we wanted to promote OA content in the discovery process, and Lean Library’s latest development of its plugin to favour the delivery of the OA alternative before the default of the subscription version, is aligned with our values (considerations of versioning aside).
So we’re aiming to bring Lean to Cambridge researchers’ attention by recommending it as the plugin of choice for the period we’re in the transition to “immediate, free and unrestricted access” for all. It is only Lean that is providing the 24-hour updated and context-sensitive linking to our EZproxy server for off campus delivery of subscription content plus promoting OA alternative versions via the deployment of the Unpaywall database. The feedback from the Office of Scholarly Communication is favourable and the statistics support the positivity that we hear from our users (for the last year 66,731 for Google Scholar enhanced links; 49,556 article alternative views; a rough estimate against our EZproxy logs showing a probable 2/5 of off campus users are accessing the proxy via Lean).
One area of concern is the ownership of Lean by SAGE Publications, in contrast to the ownership say of Unpaywall as a project of the open-source ImpactStory, and what this means for users’ privacy. The concerns are shared by other libraries implementing Lean.[5] Our approach has been to make the extension’s privacy policy as prominent as possible on our page dedicated to promoting Lean, and to engage with Lean in depth over users’ concerns. We are satisfied with the answers to our questions from Lean and that our users’ data is adequately protected. Even in a rapidly changing arena for OA discovery tools the balance is not so fine when it comes to recommending installation of the Library Access plugin over a preference for the illegitimate and risk-prone SciHub.
Libraries’ discovery servicesare geared for subscription content
Allowing for influence of searchers’ discipline on choice of discovery service, it’s little surprise that the traditional library catalogue, even when upgraded to a web scale discovery service, prejudices inclusion of subscription over OA content. Of course it does, because this is the content the libraries pay for in the traditional subscription model and the discovery system is pretty much built around that. iDiscover is Cambridge’s discovery space for institutional subscriptions and print holdings of the University’s libraries and within iDiscover Open Access repository content has been enabled for search. Further, the pipe for the institutional repository content (Apollo) is established.
Nonetheless Cambridge will be looking to take advantage of the forthcoming link resolver service for Unpaywall. This is due for release in November 2019 and will surface a link to search Unpaywall from iDiscover when subscription content is unavailable. This link should kick in usually when the search in iDiscover is expanded beyond subscription content, and a form of which has been enabled already by at least one university by including the oadoi.org lookup in the Alma configuration.
The righting moment in the angle of list is that point a ship must find to keep it from capsizing, and Library discovery system providers’ integration with OA feels a bit like that – the OA indication was included in the May 2018 iDiscover release and suppliers have been working with CORE for inclusion of CORE content since 2017. That righting moment may be just over the horizon as integration with Unpaywall arrives, and the “competition” element dissipates, as the consultancy JISC used to review the OA discovery tools commented: “As the OA discovery landscape is crowded, OA discovery products compete for space and efficacy against established public infrastructure, library discovery services and commercial services”.[6]
A diffuse but developing landscape
Easy-to-install and effective to use, the OA discovery tools we are promoting are still widely thought of as at best providing a patch, a sticking-plaster, to the problem. A plethora of plugins is not necessarily what the researcher wants, or is attracted by, however necessary the plugin may be to saving time and exposing content in discovery. Possibly the really telling use case has yet to be tried wherein the plugin comes into its own in a big deal cancellation scenario.
Usage statistics for the Lean Library Access plugin are probably a reflection of the fact that the provision of most article content that is required by the University is available via IP access as subscription, and the need for the plugin is almost entirely limited to the off campus user. The Lean plugin’s relatively modest totals are though consistent with reports of plugin adoption by institutions that have cancelled big deals. The poll of the Bibsam Consortium members revealed 75% of researchers did not have any plug-in installed; the percentage for the University of Vienna in particular was 71%; the KTH Royal Institute of Technology authors “rarely used” a plugin.[7]
Another conjecture is that there is an antipathy to any plugin that could be collecting browsing history data and however “dumb” and programmatically-erased, the concern over privacy is such that the universal adoption libraries may hope for is unachievable. The likeliest explanation is possibly around the tipping-point from subscription to OA, and despite the Apollo repository’s usage being one of the highest in the country (1.1 million article downloads from July 2018 to July 2019), Cambridge’s reading of Gold OA is c. 13% of total subscription content, including journal archives. A comparison with the proportions of percentage views by OA types in Unpaywall’s recently published data (cited above) suggests this is on the low side in terms of worldwide trends, but it must be emphasized this is a subset of OA reading and excludes green, hybrid, and bronze. Just consider for instance the 1.5 billion downloads from arXiv globally to date.[8] Similarly, the stats from Unpaywall are overwhelmingly persuasive of the success of the plugin, as of February 2019 it delivered a million papers a day, 10 papers a second.
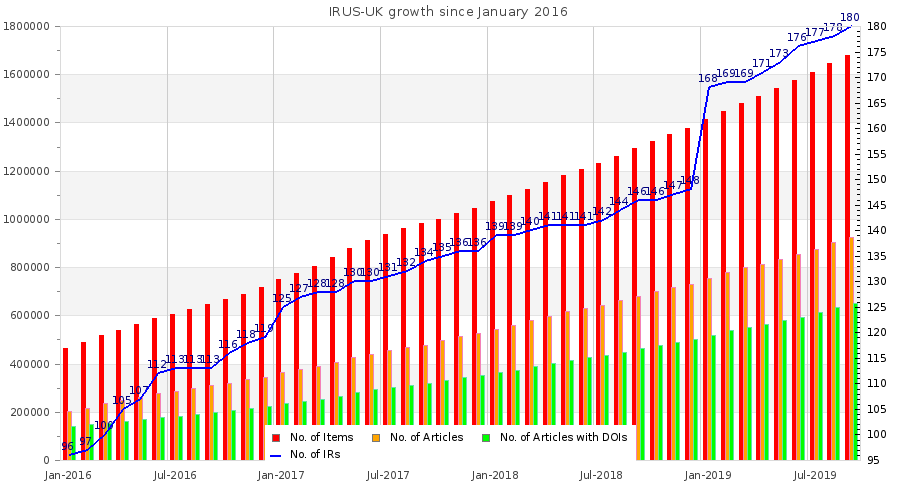
IRUS-UK growth of open access items since January 2016 (The red bars indicate total items, orange bars number of articles and green bars number of articles with DOIs. The blue line indicates the number of institutional repositories)
The inspirational statistician and “data artist” Edward Tufte wrote:
We thrive in information-thick worlds because of our marvellous and everyday capacities to select, edit, single out, structure, highlight, group, pair, merge, harmonize, synthesize, focus, organize, condense, reduce, boil down, choose, categorise, catalog, classify, list, abstract, scan, look into, idealize, isolate, discriminate, distinguish, screen, pigeonhole, pick over, sort, integrate, blend, inspect, filter, lump, skip, smooth, chunk, average, approximate, cluster, aggregate, outline, summarize, itemize, review, dip into, flip through, browse, glance into, leaf through, skim, refine, enumerate, glean, synopsize, winnow the wheat from the chaff, and separate the sheep from the goats.[9]
There’s thriving and there’s too much effort already. Any self-respecting OA plugin user will want to winnow, and make their own decisions on the plugin(s). In a less than 100% OA world, that combination of subscription and OA connection separated from physical location (on/off campus) is a critical advantage of the Lean Library offering, combined as it is with the Unpaywall database. Libraries will find much to critique in the institutional dashboards or analytics tools now built on top of some plugins (e.g. distinction of the physical location when accessing the alternative access version in the Kopernio usage for instance).
From the OA plugin user’s perspective, the emerging cutting edge is currently with the CORE Discovery plugin, as reported at the Open Repositories 2019 conference, in the “first large scale quantitative comparison” of Unpaywall, OA Button, CORE OA Discovery and Kopernio. This report reveals important truths for OA plugin critical adopters, for instance showing less than expected overlap in comparison of the plugins’ returned results from the test sample of DOIs, and the assertion “we can improve hit rate by combining the outputs from multiple discovery tools”.[10]
It’s become popular for our present day Johnson to quote his namesake, so in that vogue we should expect the take-up of Lean Library and CORE Discovery to bring closer that “resistless Day” when researchers the world over get “immediate, free and unrestricted access to all of the latest, peer-reviewed research” and the “misty Doubt” over the OA discovery landscape will be lifted.[11]
[1]
Flanagan, D. (2018). Open Access Discovery Workshop at the British Library, Living Knowledge blog 18 December 2018.
DOI: https://dx.doi.org/10.22020/v652-2876
[11] Johnson, S., In Eliot, T. S., Etchells, F., Macdonald, H., Johnson, S., & Chiswick Press,. (1930). London: a poem: And The vanity of human wishes. London: Frederick Etchells & Hugh Macdonald. l. 146.
Published Monday 21 October 2019
Written by James Caudwell (Deputy Head of Periodicals & Electronic Subscriptions Manager, Cambridge University Library)
The session was aimed at families, to show them that there is a world of research available to the general public stored on Apollo, the University’s repository – and it’s all cool stuff.
It was also aimed at researchers, to get them thinking about new ways to make their research available to a general public – including uploading their research on to the Apollo repository.
At the end of each story the audience were challenged to interpret the stories and research in their own way.
Here’s what happened during the morning.
Labour Pains: Scenes of Birth and Becoming in Old Norse Legendary Literature
The research
Kate Olley’s article looks at the drama of childbirth as depicted in Old Norse legendary literature. This article made a great beginning to the session, because it looks into the power of story to give an insight into the past. Childbirth stories are fascinating and informative because they are such important moments – ‘moments of crisis’ not just for an individual but for a whole society. They show so much about a culture, from the details of everyday life, to a picture of a society’s values and structure. Also, unlike stories of great battles and adventures, they put women and everyday life at the centre of the story.
The story
I retold one of the stories from Kate’s article, ‘Hrolf and the elvish woman’ from the saga of Hrolf the Walker. An elvish woman summons Hrolf, a king who has fallen on hard times, to help her daughter who is under a curse. She has been in labour for 19 days, but cannot give birth unless she is touched by human hands.
Kate pointed out some things the story shows us: the extreme danger of childbirth in those times; and the way a birth changes everybody’s role. The woman becomes a mother, but the fortunes of Hrolf the midwife are also changed for ever.
The challenge
We talked about how people still tell childbirth stories, and they often have the same mythic resonances as old Icelandic saga. Is there a story you tell your children about when they were a baby? (or a story that your parents tell you?)
Revolutionising Computing Infrastructure for Citizen Empowerment
The research
‘Internet dragon’
Noa Zilberman explains that almost every aspect of our lives today is being digitally monitored: from our social networks activity, through online shopping habits to financial records. Can new technology enable us to choose who holds this data? Her research, based on highly technical computer engineering, addresses a social issue that Noa feels passionate about. I chose a story that was a metaphor for her research, with a hero taking on the might of a huge and greedy dragon.
The story
‘Dragon’
I based the story on the epic account of Beowulf fighting the dragon, which reflected Noa’s passion and how important she felt the issues raised by her research are to society in general. But, as is the way with story, more links emerged during the telling. The flickering flames of the dragon’s cave, reflected the heat emitted by internet server farms. The ease with which a thief can steal gold from the hoard, and the potential harm this can do, proved highly topical. When the hero asks the blacksmith to make a shield of metal to protect him from the dragon’s breath, Noa produced her secret weapon: a programmable board, not more than six inches long, which enables data to be moved more efficiently by individual computers.
The challenge
It can be hard to visualise what ‘the internet’ really is. What might an ‘internet dragon’ look like? Can you draw one?
The provenance, date and significance of a Cook-voyage Polynesian sculpture
The research
Trisha Bierspaper sheds light on the shifting sands of anthropological investigation. It has a particular Cambridge link: she uncovers the secrets of a wooden carving brought back from Captain Cook’s voyage to the Pacific in the 18th Century. The mysterious carving – of two figures and a dog – is now the logo of the Museum of Archaeology and Anthropology.
The story
Two men and pig
As I searched for a Polynesian story about two men and a dog, I discovered many of the same factors that Trisha highlights. Stories travel across the Pacific Ocean just as commerce, people, and artworks do, making it hard to pinpoint the source of the story.
The story I chose, about the deity/hero Maui, turning his annoying brother-in-law, Irawaru, into the first dog, fits only partially – just like the many theories about the carving. Stories about Maui are known all over Polynesia: but the trickster Maui from New Zealand, where this story comes from, is different from the godlike Maui of Tahiti, the carving’s likely provenance. Like the carving, the stories of Maui have travelled to the Western world, in films like Moanna, as well as to Cambridge. Stories, which can’t be carbon-dated like the carving, shift and change just like the dog Irawaru.
The challenge
Not knowing the true story can set our imaginations free! I asked the audience to draw or write their own story about two men and a dog.
Treated Incidence of Psychotic Disorders in the Multinational EU-GEI Study
The research
Hannah Jongsma’s research looks at the risk of developing a psychotic disorder, which for a long time was thought to be due to genetics. She finds that it is influenced by many factors – both genetic and environmental – for example the risk is higher in young men and ethnic minorities.
The story
I paired the story with a sinister little tale from Grimm, Bearskin, about an outsider who is rejected by society because of his wild appearance – he wears the unwashed skin of a ferocious bear and lives like a wild man. It touched the issues of Hannah’s research at many points. The hero is a rootless and penniless young man far from home – a situation identified as high-risk in Hannah’s study. His encounter with a wild bear with whom he swaps coats is the stuff of hallucination. Like psychosis, in Hannah’s view, the problem is partly one of the way society views the outsider. And, as in Hannah’s study, being accepted by a family and given emotional support is a protection against psychosis. The remarkable thing about this this wonder-tale, so far removed from reality, was how it opened up a wide-ranging conversation about the research. Its far-fetched images helped us explore the issues of real-life research. Hannah was surprised that her research could be re-envisioned and presented in such a different way.
The challenge
Using the ideas from Hannah’s paper, suggest an alternative ending to the story.
Determining the Molecular Pathology of Inherited Retinal Disease
The research
‘DNA helix’
Crina Samarghitean shows how bioinformatics tools help researchers find new genes, and doctors find diagnosis in difficult disorders. Her article looks at better treatment and quality of life for patients with primary immunodeficiencies, and focuses on inherited retinal disease which is a common cause of visual impairment.
The story
The story of the telescope, the carpet and the lemon turned out to be a celebration of the possibilities of medical research with bioinformatics. Three brothers search for the perfect gift to win the heart of the princess, and find that these three magical objects allow them to save her life. This piece of research was the first one I tried to find a story for, and it seemed to be the hardest to translate into non-specialist language, until Crina said ‘I see the research as a quest for treasure: someone who has looked everywhere for a cure for their illness comes to this data-bank, and it’s like a treasure chest with the answer to their problem.’
The challenge
Crina is already committed to the idea that the arts can be used to interpret science. She has made artworks inspired by the gene sequences she has been working on. The challenge was to make pictures inspired by Crina’s paintings and models.
Last week, Cambridge celebrated a huge milestone – the deposit of the 1000th dataset to our repository Apollo since the launch of the Research Data Facility in early 2015. This is the culmination of a huge amount of work by the team in the Office of Scholarly Communication, in terms of developing systems, workflows, policies and through an extensive advocacy campaign. The Research Data team have run 118 events over the past couple of years and published 39 blogs.
In the past 12 months alone there have been 26000 downloads of the data in Apollo. In some cases the dataset has been downloaded many times – 170 – and the data has featured in news, blogs and Twitter.
An event was held at Cambridge University Library last week to celebrate this milestone.
Opening remarks
The Director of Library Services, Dr Jess Gardner opened proceedings with a speech where she noted “the Research Data Services and all who sail in her are at the core of our mission in our research library”.
Dr Gardner referred to the library’s long and proud history of collecting and managing research data that “began on vellum, paper, stone and bone”. The research data of luminaries such as Isaac Newton and Charles Darwin was on paper and, she noted “we have preserved that with great care and share it openly on line through our digital library.”
Turning to the future, Dr Gardner observed: “But our responsibility now is today’s researcher and today’s scientists and people working across all disciplines across our great university. Our preservation stewardship of that research data from the digital humanities across the biomedical is a core part of what we now do.”
“In the 21st century our support and our overriding philosophy is all about supporting open research and opening data as widely as possible,” she noted. “It is about sharing freely wherever it is appropriate to do so”. [Dr Gardner’s speech is in full at the end of this post.]
Perspectives from a researcher
The second speaker was Zoe Adams, a PhD student at Cambridge who talked about the work she has done with Professor Simon Deakin on the Labour Regulation Index in association with the Centre for Business Research.
Ms Adams noted it was only in retrospect she could “appreciate the benefit of working in a collaborative project and open research generally”. She discussed how helpful it had been as an early career researcher to be “associated with something that was freely available”. She observed that few of her peers had many citations, and the reason she did was because “the dataset is online, people use the data, they cite the data, and cite me”.
Working openly has also improved the way she works, she explained, saying “It has given me a new perspective on what research should be about. … It gives me a sense that people are relying on this data to be accurate and that does change the way you approach it.”
View from the team
The final speaker was Dr Lauren Cadwallader, Joint Deputy Head of the OSC with responsibility for the Research Data Facility, who discussed the “showcase dataset of the data that we can produce in the OSC” which is taken from usage of our Request a Copy service.
Dr Cadwallader noted there has been an increase in the requests for theses over time. “This is a really exciting observation because the Board of Graduate studies have agreed that all students should deposit a digital copy of their thesis in our repository,” she said. “So it is really nice evidence that we can show our PhD students that by putting a copy in the repository people can read it and people do want to read theses in our repository.”
One observation was that several of the theses that were requested were written 60 years ago, so the repository is sharing older research as well. The topics of these theses covered algebra, Yorkshire evangelists and one of the oldest requested theses was written in 1927 about the Falkland Islands. “So there is a longevity in research and we have a duty to provide access to that research, ” she said.
The music played at the event was complied by Tony Malone and covers almost 1000 years of music, from Laura Cannell’s reworking of Hildegard of Bingen, to Jane Weaver’s Modern Cosmology. There are acknowledgments to Apollo, and Cambridge too. The soundtrackis available for those interested in listening.
This achievement is entirely due to the incredible work of the team in the Research Data Facility and their ability to engage with colleagues across the institution, the nation and the world. In particular the vision and dedication of Dr Marta Teperek cannot be understated.
In the words of Dr Gardner: “They have made our mission different, they have made our mission better, through the work they have achieved and the commitment they have.”
The event was supported by the Arcadia Fund, a charitable fund of Lisbet Rausing and Peter Baldwin.
Published 21 September 2017 Written by Dr Danny Kingsley
Speech by Dr Jess Gardner
First let us begin with some headline numbers. One thousand datasets. This is hugely significant and a very high level when looking at research repositories around the country. There is every reason to be proud of that achievement and what it means for open research.
There have been 26000 downloads of that data in the past 12 months alone – that is about use and reuse of our research data and is changing the face of how we do research. Some of these datasets have been downloaded 117 times and used in news, blogs and Twitter. The Research Data team have written 39 blogs about research data and have run 118 events, most of these have been with researchers.
While the headline numbers give us a sense of volume, perhaps let’s talk about the underlying rationale and philosophy behind this, which is core.
Cambridge University Library has a 600 year old history we are very proud of. In that time we have had an abiding responsibility to collect, care for and make available for use and reuse, information and research objects that form part of the intrinsic international scholarly record of which Cambridge has been such a strong part. And the ability for those ideas to inspire new ideas. The collection began on vellum, paper, and stone and bone.
And today much of that of course is digital. You can’t see that in the same way you can see the manuscripts and collections. It is sometimes hard to grasp when we are in this grand old dame of a building that I dare you not to love. It is home to the physical papers of such greats as Isaac Newton and Charles Darwin. Their research data was on paper and we have preserved that with great care and share it openly on line through our digital library. But our responsibility now is today’s researcher and today’s scientists and people working across all disciplines across our great university. Our preservation stewardship of that research data from the digital humanities across the biomedical is a core part of what we now do.
And the people in this room have changed that. They have made our mission different, they have made our mission better through the work they have achieved and the commitment they have.
Philosophically this is very natural extension of what we have done in the Library and the open library and its great research community for which this very building is designed. Some of you may know there is a philosophy behind this building and the famous ‘open library Cambridge’. In the 19th century and 20th century that was mostly about our open stack of books and we have quite a few of them, we are a little weighed down by them.
Our research data weighs less but it is just as significant and in the 21st century our support and our overriding philosophy is all about supporting open research and opening data as widely as possible. It is about sharing freely wherever it is appropriate to do so and there are many reasons why data isn’t open sometimes, and that is fine. What we are looking for is managing so we can make those choices appropriately, just as we have with the archive for many, many years.
So whilst as there is a fantastic achievement to mark tonight with those 1000 datasets it really is significant, we are really celebrating a deeper milestone with our research partners, our data champions, our colleagues in the research office and in the libraries across Cambridge, and that is about the changing role in research support and library research support in the digital age, and I think that is something we should be very proud of in terms of what we have achieved at Cambridge. I certainly am.
I am relatively new here at Cambridge. One of the things that was said to me when I was first appointed to the job was how lucky I was to be working at this University but also with the Office of Scholarly Communication in particular and that has proved to be absolutely true. I like to take this opportunity to note that achievement of 1000 datasets and to state very publicly that the Research Data Services and all who sail in her are at the core of our mission in our research library. But also to thank you and the teams involved for your superb achievements. It really is something to be very proud of and I thank you.
To celebrate Open Access Week 2016, the Office of Scholarly Communication (OSC) officially launched ‘Apollo’, the University of Cambridge’s upgraded open access repository.
Researchers, University research staff and librarians gathered at the University’s Engineering Department to see a demonstration of the new features of Apollo, speak to some of the University’s Open Access Champions and raise a glass to launch the service.
The repository stores a range of content and provides different levels of access, but its primary focus is on providing open access to the University’s research publications. Apollo forms an important part of the University’s provision for meeting research funder requirements for open access, enabling ‘Green’ access to publications. The launch of the upgrade comes at an exciting time for the Office of Scholarly Communication, as the repository has recently received its 10,000th upload.
The Cambridge University Office of Scholarly Communication looks after all aspects of scholarly communication within the University. This ranges across the entire research lifecycle from searching for information and collaborators, through to authoring and copyright issues and finally the publication and dissemination process, leading into assessment. The OSC has responsibility for the open access and open data programs at the University in terms of compliance with funders’ policies, and delivers and manages the University’s digital repository, Apollo.
Cambridge University was one of a handful of ‘testbed ‘ institutions that participated in the early deployment and development of DSpace, and has been running a DSpace repository for over a decade. Over that time, Apollo has participated in a number of externally funded projects intended to better understand researcher requirements or improve the services it offers. These include: Incremental, DataTrain and PrePARe, which developed resources to support research data management and EPIC and Keeping Research Data Safe (KRDS), which focused on the repository’s preservation services.
Upgraded features
With the support of RCUK, the OSC have spent £43,000 to upgrade the repository. Cambridge is now leading the country by running DSpace Version 5.4, the most recent and most stable version of the application. This has given Apollo a modern and improved user-friendly interface.
Since the upgrade in May 2016, the repository has had close to 2 million views from actual people (not machines!)
The upgrade means we can now increase the services offered by the repository. Digital Object Identifiers, or DOIs, can be minted in-house. The Open Access team has minted over 6000 DOIs since May for articles, theses, datasets and other research outputs.
In addition, people identifiers – Author ORCIDs – are now displayed in the repository. The repository is interoperable with other systems and sends ORCIDs to Datacite, which might allow repository items to be automatically populated into Authors’ ORCID profiles in the future.
Perhaps the most exciting integration is with the University’s publication management system Symplectic, allowing for easier reporting of Open Access compliance.
Request a Copy
Part of the upgrade involved the introduction of a new feature called ‘Request a Copy’, designed to open up the University’s most current research to a wider audience. ‘Request a Copy’ operates on the principle of peer-to-peer sharing – if an item in Apollo is not yet available to the public, a repository user can ask the author for a copy of the item. Authors sharing copies of their work on an individual basis falls outside the publisher’s copyright restrictions; here, the repository is acting as a facilitator to a process which happens anyway.
The Request a Copy button has been much more successful than we anticipated, particularly because there is no actual ‘button’. By the end of September 2016 (four months after the introduction of ‘Request a copy’), we had received 1120 requests (approximately 280 requests per month), with two thirds for articles. Apart from a small number of requests for datasets, the remaining third were for theses.
Of the requests for articles during this period, 38% were fulfilled by the author sending a copy via the repository, and 4% were rejected by clicking the ‘Don’t send a copy’ button.
Of the articles requested during this period 45% were yet to be published. The large number of requests made prior to publication indicates the value of having a policy where articles are submitted to the repository on acceptance rather than publication – there is clearly interest in quickly accessing this research, rather than waiting for publication.
Open Access Week
The Apollo launch was the closing event of Open Access Week at the OSC. Established by SPARC and partners in the student community in 2008, International Open Access Week is an opportunity to take action in making openness the default for research—to raise the visibility of scholarship, accelerate research, and turn breakthroughs into better lives. The OSC also released a daily programme of announcements, blog posts and live-streamed events, which are spotlighted on the OA Week webpage, and celebrated this year’s theme of ‘Open in Action’.
As part of Open Access Week 2016, the Office of Scholarly Communication is publishing a series of blog posts on open access and open research. In this post Dr Matthias Ammon looks at theses and their use.
It may sound obvious, but PhD theses are a huge reservoir of original research content, given that each thesis represents at least three or four years’ focussed engagement with a specialised research topic. Traditionally, however, the results of this work have not been easily accessible.
A print copy of the approved thesis would be deposited in the library of the university where the PhD was undertaken so that access was mainly restricted to other members of that university. Interested readers have to travel to visit the library or rely on frequently costly interlibrary loans. While some of the research contained in theses would be published in articles or monographs, this still means that an enormous amount of research was and is effectively locked away.
Increasing access
With the changes in technology in recent decades allied with the rise of Open Access and institutional repositories, the accessibility of PhD theses in general has improved. In Australia, the Australian Digital Theses program began in 1998, expanding to the Australasian Digital Theses program in 2005. This used VT-ETD software to host digital theses at individual institutions which were collated to one search engine. The ADT website, a central metadata repository, was hosted at the University of New South Wales. This was decommissioned in 2011 as theses were migrated to their various institutional repositories. All Australian theses are now findable in Trove, the National Library of Australia’s Trove service. There are 334, 000 theses listed in Trove of which over 119,000 are available online.
A significant number of UK universities now require the deposit of a digital copy of a thesis in the university’s repository as a condition for awarding the PhD degree. Usually this entails making the thesis openly available although embargoes may be placed for reasons of confidentiality or commercial concerns. In addition, PhD students funded by any of the UK research councils under the RCUK Training Grant are required to make their theses available Open Access.
Although it is not yet mandatory at the University of Cambridge for PhD students to provide a digital copy of their thesis, students can voluntarily upload their approved dissertations to the institutional repository, Apollo. Approximately one in 10 PhD students do so. In the next couple of weeks, the Office of Scholarly Communication is embarking on a pilot for the systematic submission of digital theses with selected departments.
Finding theses
There are national and international repositories that aggregate access to PhD theses, such as the British Library’s EThOS (for the UK) or DART-Europe (for European universities), making it easier for interested researchers to find relevant material without having to trawl through individual repositories.
Proquest Theses and Dissertations (PQDT) is a database of dissertations and theses published digitally or in print. Note these are made available for a fee that does not benefit the author. [In September 2017 ProQuest contacted us to say they do pay royalties. Their policy is here.] In addition access to PQDT may be limited depending on local library licensing arrangements.
Looking to the past
So while it is looking likely that most future PhD theses will be available online (either freely or requestable), what about the vast number of PhD theses written up to this point? For context, Cambridge alone holds over 40,000 printed theses, with approximately 1100 being added every year. Approximately 2,000 of these have been digitised at the request of individuals wishing to have access to the theses.
Last year we ran an ‘Unlocking Theses’ project to increase the number of Open Access theses in the repository, which stood at about 600 at the beginning of 2015. The Library also held over 1200 scanned theses on an internal server. The Unlocking Theses project added all of these scanned theses held by the Library into the University repository. The Development and Alumni Office were able to provide contact details for just over 600 of these authors. The majority of these authors have now been contacted and we have had a 35% positive response rate from them.
As of today we hold 2257 theses in the repository of which half are Open Access. The remaining theses are currently held in a Restricted Theses Collection but the biographical information about these theses is searchable. Approximately one third of requests we have from our Request a Copy service is for these theses. In addition some authors have found their restricted thesis online and requested we open access to it.
Cambridge is currently working with the British Library to digitise some of the 14,000 Cambridge theses they hold on microfilm. Our finances do not stretch to the whole corpus, so we have decided to digitise ten percent. This has meant a process to determine which theses we choose to have digitised. Considerations have included the quality of digitisation from microfilm for typeset versus typewritten theses (and indeed whether the thesis is printed single or double sided because of shadowing). We have also chosen theses on the basis of those disciplines are highly requested from our Digital Content Unit. This has proved to be challenging, not least because of the difficulty of determining disciplines of theses from our library catalogue.
We are hoping to upload these theses to the repository towards the end of the year, and with the addition of several hundred theses that have been digitised this year from the Digital Content Unit will double the number of theses we hold in the repository.
Considerations
There are several issues that need to be considered before theses can be made available openly. The first concerns third party copyright, that is to say the inclusion of quotations, images, photographs or other material that does not represent original work on behalf of the thesis author but has been taken from previously published work. There is generally no problem with including such material in the copy of the thesis submitted for examination and the print version deposited in the University library, but making the thesis freely available online constitutes a change of use and requires separate permissions. This is a problem that applies to both current and older theses and requires checks on behalf of the author and possibly the library.
Another issue related to copyright is the author’s permission to make the thesis available which is necessary because the author retains the copyright for his work. For current theses, this permission can be incorporated into the submission process, either as part of the requirement for the PhD or by the author signing an agreement when the thesis is voluntarily uploaded.
However, it is not so easy to obtain permission for retrospective digitisation as we discovered during our Unlocking Theses project. The contact details of alumni are not always known and in cases where the original author is deceased it may be challenging to establish the copyright holder, making it difficult to obtain an explicit ‘opt-in’ permission. Finally, there are financial considerations as the digitisation of large number of theses requires a significant outlay for staff, equipment and administrative costs.
Big projects
In recent years, a number of universities have undertaken large-scale digitisation projects of their holdings of PhD theses and have dealt with the permission issue in different ways.
The University of Surrey interpreted the permission to share copies of theses for research purposes as applying to digital as well as print format and, with support from Proquest, digitised their entire thesis collection. They are prepared to take down theses upon request of the author but to date none have been received.
The University of Leicester’s digitisation project states that they ‘have contacted as many former students as possible about this but do not have contact details for everyone’, they otherwise follow a similar policy of take-down on request.
The London School of Economics (LSE) also digitised their back catalogue of theses and contacted alumni with an opt-out option, i.e. if no response was received the thesis would be uploaded. LSE has also made statistics about downloads of their digitised theses available, showing that there is a real demand for access to this kind of research output. By comparison, Cambridge on average receives approximately two requests for non-digitised theses per day.
The experience of these UK universities also appears to indicate that alumni are for the most part happy to see their theses made openly available. If more institutions follow suit and dedicate funding to opening up the research undertaken by generations of students this large reservoir of research will no longer remain untapped.
There are other challenges related to digital theses that still remain to be solved, such as the problem of linking theses to their associated data and the question of persistent identifiers to seamlessly integrate the output of both individual researchers and institutions. In the future, consideration should be given to non-text or multimedia PhDs, as was debated at a recent panel discussion at the British Library.
For now though, opening up access to decades’ or even centuries’ worth of scholarship sitting on university library shelves in the form of physical copies of PhD theses sounds like a good start.
Published 26 October 2016 Written by Dr Matthias Ammon and Dr Danny Kingsley