Dr. Sacha Jones and Dr. Samuel Moore, Office of Scholarly Communication, Cambridge University Libraries
The Open Research at Cambridge conference took place between 22–26 November 2021. In a series of talks, panel discussions and interactive Q&A sessions, researchers, publishers, and other stakeholders explored how Cambridge can make the most of the opportunities offered by open research. This blog is part of a series summarising each event.
As part of the Cambridge Open Research conference, the Office of Scholarly Communication hosted a ‘101’ session on open research, covering the basics and answering queries for the audience on all aspects of open access publication and open data. With over 80 participants, we were thrilled with the response and wanted to recap some of the topics we covered in this post.
Firstly, as we discussed in the session, it is easy to assume that open research is simply an issue for the sciences rather than all academic disciplines. Practices such as open access and open data have been taken up widely in the sciences, although in different ways, and there is a common association with science and openness. This is compounded by the fact that in many European countries Open Science is inclusive of arts and humanities scholarship and so is functionally equivalent to open research. At the OSC, we are keen to support open practices across all disciplines while being sensitive to different ways of working. We are guided by the university’s Open Research Position Statement that requires work to be ‘as open as possible, as closed as necessary’.
After an introduction to open research, Sam then outlined the key issues in open access, including the different licences for making your research open access, the differences between green and gold open access, and the many and various reasons for making your work open access. Open access allows us to reach new audiences, improve the economics of research access, and reassess knowledge production and dissemination in a digital world. We also learned about open access monographs, the complex policy landscape and the various ways in which you can make your research open access through repositories and journals. The OSC’s Open Access webpages are an excellent set of resources for learning more.
We then moved onto open data – research data shared publicly – and how this fits into open research (see the University’s policy framework on research data). After highlighting that all research regardless of discipline generates or uses data of one kind or another (e.g. text, audio-visual, numerical, etc.), Sacha posed a series of questions with answers, anticipating what the audience might want to know more about. Do I have to share my data? What data do I share – is it meant to be everything from my research? My data contains sensitive information so I can’t share my data, or can I? How do I share my data? I don’t want to be criticised after making my data open, so how can I prevent this? How can I stop someone else from taking my data, using it, and getting all the credit? The OSC’s Research Data website contain information about data management and data sharing, and check out our list of Cambridge Data Champion experts to see if there’s anyone who’s volunteered to be a local source of data-related advice in your department or discipline.
We are always available as a source of support and guidance in all matters relating to open research and encourage you to contact us if you have any questions. The OSC has webpages on open research and sites dedicated to both open access and research data. For general open research enquires, we can be emailed at info@osc.cam.ac.uk, for open access at info@openaccess.cam.ac.uk and for data at info@data.cam.ac.uk. There are also a number of training sessions provided throughout the year and online that relate to the topics covered in this session. If you think that those in your department or institute at Cambridge would like to know more about the topics covered here then please do get in touch as we’d be happy to speak to these and answer any questions you may have.
Cambridge Data Week 2020 was an event run by the Office of Scholarly Communication at Cambridge University Libraries from 23–27 November 2020. In a series of talks, panel discussions and interactive Q&A sessions, researchers, funders, publishers and other stakeholders explored and debated different approaches to research data management. This blog is part of a series summarising each event.
The first day of Cambridge Data Week 2020 kicked off with a tantalisingly open question: who are the winners and losers of good data practices? This question was addressed via two different perspectives: those of a funder, provided by Dr Georgie Humphreys (Wellcome), and of a publisher, provided by Dr Catriona MacCallum (Hindawi). Discussion of this topic during presentations and the Q&A session looked through various (but not mutually exclusive) lenses, including those of data sharing, quality, ethics, and research culture. Funder mandates for data sharing and what these have achieved (e.g. saving research funds related to data reuse) were reflected upon, as were disciplinary differences between STEMM, social sciences, arts and humanities. There was also a discussion of evidence relating to shifts in research culture and if this is pointing to better data practices. As a whole, the webinar explored a broader view of good data practices, the consequences of these, and the progress being made in embedding good data management in research.
Topical for this year, both speakers discussed data sharing related to Covid-19 research. Catriona stated that Covid has exposed systemic flaws in the existing system (in relation to data sharing), and Georgie highlighted some surprising results regarding data availability statements in Covid-related articles. The CARE Principles for Indigenous Data Governance were also bought to the fore by Catriona, who argued for attention to be placed on potential power issues surrounding data sharing. These are a set of principles, complementary to the FAIR principles, but which encourage the open research movement to fully engage with Indigenous Peoples rights and interests. A pervasive undercurrent ran throughout the webinar – research culture and some problems therein. These were addressed explicitly by both speakers, with both stating that more needs to be done by institutions to implement DORA and reward researchers for their achievements and good research practices and not just according to where (i.e. in what journals) their research is published. Catriona highlighted results from a 2019 EUA report that shows that institutions have some way to go in this regard, that the value of data is not fully recognised, and that responsible research assessment is at the heart of cultural change in the right direction.
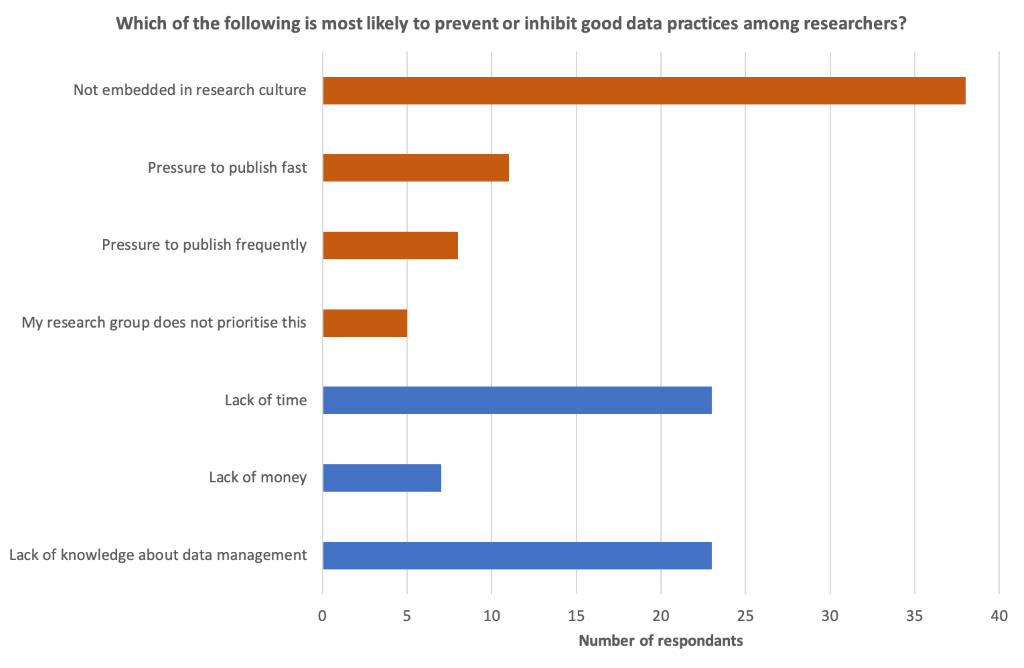
We had some great questions from the audience that were answered in the Q&A session, such as “In countries without the REF, is data sharing better?”, and “How do you get qualitative researchers on board with this?”, and “What is the role of universities in the so-called data-driven economy?”. Our audience also responded to the poll we held at the end of the webinar, where we asked participants to select one from seven given options that they regard as most likely to prevent good data practices among researchers. Resource indicators (knowledge, time, money for RDM) amounted to 46% of responses (blue in the chart below) and cultural indicators amounted to 53% (orange in the chart). Overall, the results were rather surprising but optimistic, revealing that a dominant perception among the participants is that a shift in cultural practices is one of the leading factors necessary to drive forward good data practices in research.
Figure 1. Results of the poll held during the webinar, where participants were asked to choose one of seven factors that they consider most likely to prevent or inhibit good data practices.
Audience composition
We had 274 registrations for this webinar, with just over 70% originating from the Higher Education sector. Researchers and PhD students accounted for 40% of registrations and research support staff for an additional 30%. On the day, we were thrilled to see that 164 people attended the webinar, participating from a wide range of countries.
There were a few questions we did not have time to address during the live session, so we put them to the speakers afterwards. Here are their answers:
What are the ethics of using secondary data, particularly in relation to primary versus secondary researchers’ objectives, meaning of data/methods, consent of participants, and in the case of qualitative data, the personal relationships built between researcher and participants?
Georgie Humphreys This question seems to allude to informed consent which is still a topic of active discussion in terms of what one tries to build into the original informed consent to allow subsequent secondary use down the line. There is this idea of broad consent now where a participant would consent to that particular project but they’re also consenting to their data being kept and maybe reused for other purposes related to different scientific questions, but maybe with clauses such as ‘not for commercial benefits’. There are potential concerns about re-identification but there are mechanisms for dealing with that – mechanisms which reduce risk whilst retaining value, such as anonymisation or synthetic data creation. But there are other datasets where that’s just not going to be possible, where you lose all value of the original dataset. The UKDS have a nice page on informed consent, providing information on what you put in your consent forms to enable secondary use. This needs to be thought about at the very start of the study prior to collection of the primary data.
Catriona MacCallum This question is really focusing on data privacy issues. The primary researcher collects the data, the secondary researcher reuses the data. There are ways that researchers can be given access to the data while maintaining privacy. The primary researcher is creating the relationships with participants in order to obtain data, so what does this mean ethically for those wishing to reuse the data? Safety nets do need to be put into place. Here, it’s important to raise the CARE principles again. These were the result of a working group that came about as a result of concerns about how data from indigenous people are being treated. The slogan is now ‘Be FAIR and CARE’. The CARE principles are emerging in the UN’s agenda, and UNESCO, and I’m sure it will come up with the Research Council’s too.
What are the best practices to ensure data quality?
Catriona MacCallum It depends what is meant by ‘quality’ as there are various ways of looking at this. The European Commission came up with the economic loss of not publishing failed experiments; in other words, the publication bias that results. We need to redefine what we mean by quality, integrity and again this speaks to the research culture as no one gets rewarded for publishing a failed result and in fact the researchers end up feeling embarrassed and tend not to do it. Publication bias is huge! It also applies to the humanities and social sciences as well but potentially in a different way, and there are huge biases in terms of what gets published and what is allowed to get published.
Georgie Humphreys This issue is probably a plug for the open peer review model where the filter is not at the beginning but later on. [In open peer review, authors and reviewers are aware of each other’s identity and encouraged to engage in open discussion. This makes the process more transparent, removing bias or conflicts of interest. Manuscripts are made publicly available pre-review, and reviews are published alongside the article].
Conclusion
So, who are the winners and losers of good data practices? Georgie believes that everyone, in the long term, will be a winner. If time is spent ensuring data is well-documented, well-organised, has dictionaries, is stored somewhere for the long term, then it will benefit the data creators just as much as anyone else. In the short term, she acknowledges that there may be people that find being a champion in this field a challenge for them individually, but it’s just about continuing along this journey to get to the point where everything is in place to truly reward and recognise those that have good open practices and good data management practices. Catriona says that there are so many winners: the economy, society, and science, the social sciences and humanities – all will benefit from data sharing. Taking society as an example, sharing data and sharing it well (through good research data management) will increase public trust in science, benefit public health and even help toward achieving multiple sustainable development goals.
Resources
A Covid-19 press release by Wellcome in January 2020 called on researchers, publishers and funders to share or facilitate the sharing of interim and final data as rapidly as possible. Wellcome have been exploring the impact of this statement on data sharing.
An April 2020 publication by Colavizza et al. on ‘The citation advantage of linking publications to research data’ showing that article citations are greater when they have data availability statements that include a link (e.g. DOI) to data archived in a repository.
Cambridge Data Week 2020 was an event run by the Office of Scholarly Communication at Cambridge University Libraries from 23–27 November 2020. In a series of talks, panel discussions and interactive Q&A sessions, researchers, funders, publishers and other stakeholders explored and debated different approaches to research data management. This blog is part of a series summarising each event.
Reuse of data is the final element of the FAIR principles and has long been argued as a central benefit of data sharing, allowing others access to a wealth of research and making research funding more efficient by removing the need to duplicate work. Yet we are still in the process of evaluating success in this area. This webinar brought together speakers to discuss what we know about the current state of play around data reuse, what researchers can do to increase the reuse potential of their data, and possible future developments in data reuse.
Our speakers – Louise Corti (UK Data Archive) and Tiberius Ignat (Scientific Knowledge Services) – looked at data reuse from two different perspectives. Louise focused on the reuse of UK Data Service collections, sharing some examples of their most widely used data sets, discussing what makes them popular and sharing some principles that can be used both to make data more reusable and to promote it for reuse. Tiberius discussed the prevalence of data reuse by machines and the possibility of granting machines data reuse rights.
Louise’s presentation gave an overview of the portfolio of data sets hosted by the UK Data Service, looked at their top 20 most downloaded datasets and discussed the underlying principles that have led to them being widely reused. As well as demonstrating some commonalities between these datasets, Louise also outlined the principles used by the UK Data Service to promote their collections for reuse.
Tiberius’ presentation looked at data reuse from a different perspective, serving as a call to action to share research data responsibly and protect it against the reuse of machines designed to persuade humans. One of Tiberius’ main arguments was that no research data from public projects should be made available to feed and develop persuasive algorithms.
The presentations motivated an interesting discussion covering a broad range of topics. These included the reuse of qualitative data, how we can implement ethical safeguards data reuse, the idea of data ethics as a continuum, whether we can accept positive cases of algorithmic persuasion such as to promote equality and diversity, and the possibility of creating specific licences prohibiting data reuse by persuasive algorithms. See below for a video and transcript of the session.
Audience composition
We had 341 registrations with just over 65% originating from the Higher Education sector. Researchers and PhD students accounted for nearly 37% of the registrations whilst research support staff accounted for an additional 33%. We also had registrations from at least 30 countries outside of the UK including significant attendance from Denmark, Holland, Germany and Canada. We were thrilled to see that on the actual day 187 people attended the webinar.
We held five online webinars during Cambridge Data Week and were pleased to see that nearly 25% of the participants attended more than one webinar. A total of 1364 people registered and more than 700 attended all together, with the rest possibly watching the recordings at a later date. Most of all we were pleased to welcome participants from all over the world and see how important research data management topics are globally.
Where data was available, we identified the following countries apart from the UK: Australia, Austria, Bangladesh, Brazil, Canada, Colombia, Croatia, Czech Republic, Denmark, France, Germany, Greece, Holland, Hungary, Iran, Luxembourg, Moldova, Norway, Poland, Romania, Singapore, Spain, Sweden, Switzerland, Turkey, Ukraine and the USA.
After the session ended, we continued the discussion with Louise and Tiberius looking in particular at one question posed by an audience member:
AI can always be used either for good or bad. Instead of locking-in, how can we enhance technology through data and regulation?
Tiberius Ignat I think at this point we need regulation. I’m not a big fan of using regulations, to be honest. I think it’s much better to motivate people but, in this case, it’s quite a bit of control that has been lost, so I think we should have a regulation on how research data can be reused by others. This is how the internet has been made profitable during the last decade — through non-human persuasion. All these companies that are giving so much away for free are making billions of dollars when you look at the stock market. We were not clear how they were making this profit until recently when we realised that they are doing it by changing our behaviour and I think the rest of society – including research organisations – are behind them, so we need some regulation.
A good example is with GDPR. It has been introduced to protect our data, our digital footprint. On ResearchGate or Eurosport, or any other website, we used to be asked to agree to cookies or not. Recently, a new option called “Legitimate interest” has been slipped in and our digital data is again collected – less noticeably – by invoking questionable legitimate rights. The organisations whose model is based on persuading need cookie data, so they have moved the discussion away from remaining GDPR compliant to defending their legitimate interests. They are fighting to take data away from us. We can tackle this with regulation faster but in the long term we need to educate people to be more aware. We do have licenses such as Creative Commons but I’m not sure we have the right ones to protect us.
Louise Corti There are a variety of licenses, but they are abused and it’s very hard to track along the way what has gone wrong. I quite like the UK Government’s approach with some of their statistical data that has to go through a legal gateway. Some data can be made available for research, but it has to be done for the public good. We also have the Ethics Self-Assessment Tool, which is a grid you go through provided by the Statistics Authority and it asks you to think along lots of different dimensions of ethics. This helps researchers get a better sense of what they are trying to do, but whether the people we are talking about would care about it is a very different matter. Having been in research ethics for a very long time, that is by far the best tool I’ve seen and I recommend everyone uses it. The UK Data Archive uses it to evaluate some of the projects we deal with because you find often university ethics approvals are not good enough for the Statistics Authority because often they don’t understand quantitative secondary analysis, so the ethics scrutiny is not good enough. Self-Assessment is a much more nuanced thinking about the different dimensions of ethics and it helps researchers to be a bit more reflective about what’s good and what’s not.
Conclusion
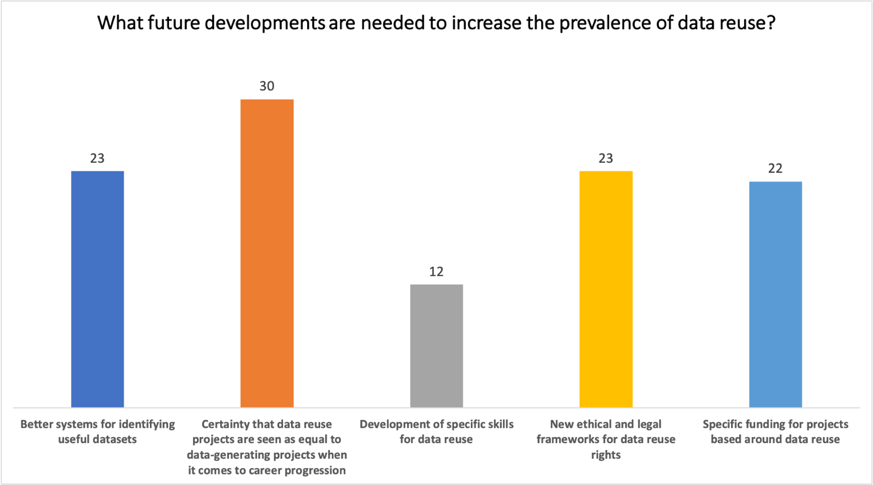
Overall, the session provided a compelling blend of both the practical and conceptual elements of data reuse, each raising questions which could have easily been entire sessions in themselves. Louise’s presentation gave an excellent overview of the UK Data Service’s approach to making their datasets more reusable and promoting them to maximise their chances of being reused. Tiberius’ session raised some interesting questions surrounding data reuse and the ethics of using algorithms to persuade humans, as well as looking at some practical options for protecting research data from reuse for nefarious ends. At the end of the session, the audience were asked to participate in a poll on “What future developments are needed to increase the prevalence of data reuse?”.
Audience responses to poll held at the end of the event
The results were unsurprising to either speaker, with each touching on the idea that a change in research culture is necessary to ensure data reuse projects are seen as equal to data-generating projects. The need for cultural change is a theme that ran throughout each of the sessions in Data Week and is perhaps one of the current major challenges in scholarly communication.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behaviour or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.