Cambridge Data Week 2020 day 1: Who are the winners and losers of good data practices?
Cambridge Data Week 2020 was an event run by the Office of Scholarly Communication at Cambridge University Libraries from 23–27 November 2020. In a series of talks, panel discussions and interactive Q&A sessions, researchers, funders, publishers and other stakeholders explored and debated different approaches to research data management. This blog is part of a series summarising each event.
The rest of the blogs comprising this series are as follows:
Cambridge Data Week day 2 blog
Cambridge Data Week day 3 blog
Cambridge Data Week day 4 blog
Cambridge Data Week day 5 blog
Introduction
The first day of Cambridge Data Week 2020 kicked off with a tantalisingly open question: who are the winners and losers of good data practices? This question was addressed via two different perspectives: those of a funder, provided by Dr Georgie Humphreys (Wellcome), and of a publisher, provided by Dr Catriona MacCallum (Hindawi). Discussion of this topic during presentations and the Q&A session looked through various (but not mutually exclusive) lenses, including those of data sharing, quality, ethics, and research culture. Funder mandates for data sharing and what these have achieved (e.g. saving research funds related to data reuse) were reflected upon, as were disciplinary differences between STEMM, social sciences, arts and humanities. There was also a discussion of evidence relating to shifts in research culture and if this is pointing to better data practices. As a whole, the webinar explored a broader view of good data practices, the consequences of these, and the progress being made in embedding good data management in research.
Topical for this year, both speakers discussed data sharing related to Covid-19 research. Catriona stated that Covid has exposed systemic flaws in the existing system (in relation to data sharing), and Georgie highlighted some surprising results regarding data availability statements in Covid-related articles. The CARE Principles for Indigenous Data Governance were also bought to the fore by Catriona, who argued for attention to be placed on potential power issues surrounding data sharing. These are a set of principles, complementary to the FAIR principles, but which encourage the open research movement to fully engage with Indigenous Peoples rights and interests. A pervasive undercurrent ran throughout the webinar – research culture and some problems therein. These were addressed explicitly by both speakers, with both stating that more needs to be done by institutions to implement DORA and reward researchers for their achievements and good research practices and not just according to where (i.e. in what journals) their research is published. Catriona highlighted results from a 2019 EUA report that shows that institutions have some way to go in this regard, that the value of data is not fully recognised, and that responsible research assessment is at the heart of cultural change in the right direction.
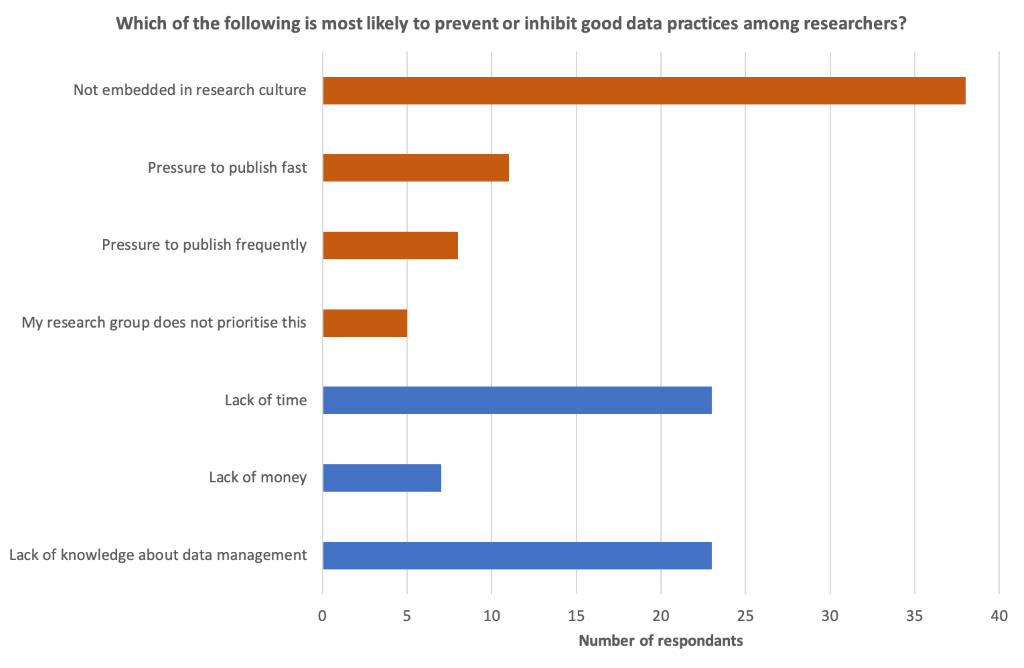
We had some great questions from the audience that were answered in the Q&A session, such as “In countries without the REF, is data sharing better?”, and “How do you get qualitative researchers on board with this?”, and “What is the role of universities in the so-called data-driven economy?”. Our audience also responded to the poll we held at the end of the webinar, where we asked participants to select one from seven given options that they regard as most likely to prevent good data practices among researchers. Resource indicators (knowledge, time, money for RDM) amounted to 46% of responses (blue in the chart below) and cultural indicators amounted to 53% (orange in the chart). Overall, the results were rather surprising but optimistic, revealing that a dominant perception among the participants is that a shift in cultural practices is one of the leading factors necessary to drive forward good data practices in research.
Audience composition
We had 274 registrations for this webinar, with just over 70% originating from the Higher Education sector. Researchers and PhD students accounted for 40% of registrations and research support staff for an additional 30%. On the day, we were thrilled to see that 164 people attended the webinar, participating from a wide range of countries.
Recording , transcript and presentations
The video recording of the webinar can be found below and the recording, transcript and presentations are present in Apollo, the University of Cambridge repository.
Bonus material
There were a few questions we did not have time to address during the live session, so we put them to the speakers afterwards. Here are their answers:
What are the ethics of using secondary data, particularly in relation to primary versus secondary researchers’ objectives, meaning of data/methods, consent of participants, and in the case of qualitative data, the personal relationships built between researcher and participants?
Georgie Humphreys This question seems to allude to informed consent which is still a topic of active discussion in terms of what one tries to build into the original informed consent to allow subsequent secondary use down the line. There is this idea of broad consent now where a participant would consent to that particular project but they’re also consenting to their data being kept and maybe reused for other purposes related to different scientific questions, but maybe with clauses such as ‘not for commercial benefits’. There are potential concerns about re-identification but there are mechanisms for dealing with that – mechanisms which reduce risk whilst retaining value, such as anonymisation or synthetic data creation. But there are other datasets where that’s just not going to be possible, where you lose all value of the original dataset. The UKDS have a nice page on informed consent, providing information on what you put in your consent forms to enable secondary use. This needs to be thought about at the very start of the study prior to collection of the primary data.
Catriona MacCallum This question is really focusing on data privacy issues. The primary researcher collects the data, the secondary researcher reuses the data. There are ways that researchers can be given access to the data while maintaining privacy. The primary researcher is creating the relationships with participants in order to obtain data, so what does this mean ethically for those wishing to reuse the data? Safety nets do need to be put into place. Here, it’s important to raise the CARE principles again. These were the result of a working group that came about as a result of concerns about how data from indigenous people are being treated. The slogan is now ‘Be FAIR and CARE’. The CARE principles are emerging in the UN’s agenda, and UNESCO, and I’m sure it will come up with the Research Council’s too.
What are the best practices to ensure data quality?
Catriona MacCallum It depends what is meant by ‘quality’ as there are various ways of looking at this. The European Commission came up with the economic loss of not publishing failed experiments; in other words, the publication bias that results. We need to redefine what we mean by quality, integrity and again this speaks to the research culture as no one gets rewarded for publishing a failed result and in fact the researchers end up feeling embarrassed and tend not to do it. Publication bias is huge! It also applies to the humanities and social sciences as well but potentially in a different way, and there are huge biases in terms of what gets published and what is allowed to get published.
Georgie Humphreys This issue is probably a plug for the open peer review model where the filter is not at the beginning but later on. [In open peer review, authors and reviewers are aware of each other’s identity and encouraged to engage in open discussion. This makes the process more transparent, removing bias or conflicts of interest. Manuscripts are made publicly available pre-review, and reviews are published alongside the article].
Conclusion
So, who are the winners and losers of good data practices? Georgie believes that everyone, in the long term, will be a winner. If time is spent ensuring data is well-documented, well-organised, has dictionaries, is stored somewhere for the long term, then it will benefit the data creators just as much as anyone else. In the short term, she acknowledges that there may be people that find being a champion in this field a challenge for them individually, but it’s just about continuing along this journey to get to the point where everything is in place to truly reward and recognise those that have good open practices and good data management practices. Catriona says that there are so many winners: the economy, society, and science, the social sciences and humanities – all will benefit from data sharing. Taking society as an example, sharing data and sharing it well (through good research data management) will increase public trust in science, benefit public health and even help toward achieving multiple sustainable development goals.
Resources
A Covid-19 press release by Wellcome in January 2020 called on researchers, publishers and funders to share or facilitate the sharing of interim and final data as rapidly as possible. Wellcome have been exploring the impact of this statement on data sharing.
‘The FAIR Guiding Principles for Scientific Data Management and Stewardship’ by Wilkinson et al. in Scientific Data (March 2016).
CARE Principles of Indigenous Data Governance. The full CARE principles are outlined here.
UKDS information on informed consent, including a downloadable model consent form with suggested wording to allow secondary data reuse.
An April 2020 publication by Colavizza et al. on ‘The citation advantage of linking publications to research data’ showing that article citations are greater when they have data availability statements that include a link (e.g. DOI) to data archived in a repository.
A European University Association (EUA) report published in October 2019 by Saenen et al. on ‘Research assessment in the transition to Open Science: 2019 EUA Open Science and Access Survey Results’.
Published 25 January 2021
Written by Dr Sacha Jones with contributions from Dr Georgie Humphreys, Dr Catriona MacCallum and Maria Angelaki.
You May Also Like
Rights retention: publisher responses to the University’s pilot
