The Cambridge Data Champions (DCs) advocate good Research Data Management (RDM) and Open Data practices to researchers locally in their departments, within Cambridge University in general, and sometimes further afield. They network with one another, exchange good methods of RDM, share ideas and, as a collective, reflect on current issues surrounding RDM, Open Data and researcher engagement, where a major shared goal is to establish best practices when it comes to research data. By attending bi-monthly forums facilitated by the Research Data Team, the DCs convene as a community, hear speakers presenting on relevant topics, and engage in workshops that will help them in their ‘championing’ activities. Following up from our latest blog which summarised how a workshop led to the creation of cartoon postcards as a new tool to add to the DCs’ resource kit for RDM advocacy, we are now reflecting on initiatives that sprung from workshops during the past year and are considering the challenges and opportunities that this programme brings as it approaches the end of its third year.
Growing
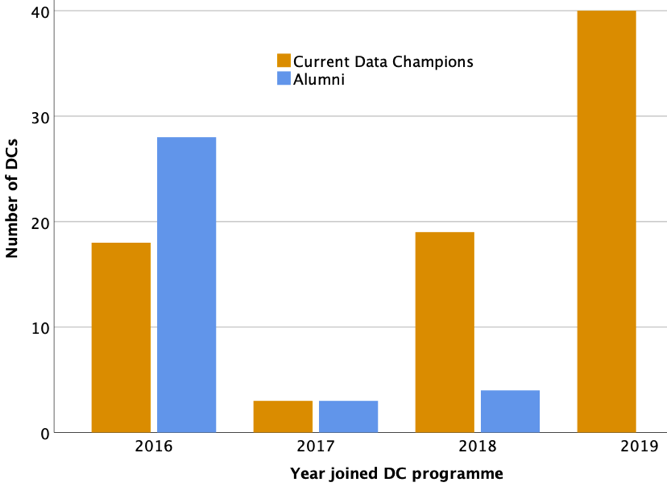
The programme started in Autumn 2016, comprising researchers who volunteered to become local community experts and advocate on research data management and sharing. Our first call welcomed 43 DCs (September 2016), our second call 20 DCs (March 2018) and the third call 40 DCs (January 2019). For simplicity, this year we also added to our statistics the “affiliate” DCs, who are colleagues who contribute to the DC community in other ways (as interested members of Cambridge’s RDM Project Group) and not necessarily through channelling their RDM efforts for the benefit of a specific department.
We are now a community comprised of 87 active DCs.
Communities within a community
Over the last year we caught ourselves using words such as the ‘old DCs’ and the ‘new DCs’ and what we really meant was ‘established DCs’ and ‘new DCs’, with the latter group being those joining the programme each year. In September we celebrate the programme’s third birthday and it is reasonable to expect that there will be more experienced DCs who have already built their networks and have, more or less, a stable offering of RDM support and an enhanced understanding of the needs of their department. On the other hand, there are those who are being welcomed into the group who seek, to differing degrees, initial support from both the RDM team and their fellow colleagues in order to become successful DCs. It is easy to imagine that different layers are being developed with different needs, both in terms of support and engagement.
Through various activities and feedback from DCs, we now have a good quantity of raw data to analyse their needs for being, as we called it, ‘a good Data Champion’. We have brainstormed ideas which we are putting into action to respond to the challenges of an ever-growing Data Champions group.
Planning
DC Welcome Pack

Every year we circulate the Data Champions Welcome Pack to coincide with the inductions we organise to welcome new DCs into the group. This year we included in the pack what it is expected from a DC when s/he joins the programme so that expectations are clearly communicated from the beginning and are the same for everybody.

Bi-monthly forums
Lightning talks have been introduced as a standard item in each forum. These have provided DCs with the opportunity to discuss aspects of RDM they are working on (e.g. new tools and techniques), or to feed back to the group on DC activities undertaken in their departments and data-related events they have attended so that the whole group can benefit. Importantly, the lightning talks have been used by DCs to problem solve, where the collective knowledge and experience of DCs attending a forum has been harnessed to address particular challenges faced by individual DCs. This is where the community aspect of the programme truly shines.
It is always a priority for us to invite speakers to forums who are external to the programme, reflecting the needs of both the new and established DCs. For example, Hannah Clements from Cambridge University’s Researcher Development Programme (RDP) spoke to the DCs at the January forum about mentoring, providing guidance on how support can be best delivered within the DC community. In the May forum, we had talks and discussions from a panel of experts working on different aspects of data archiving. The panellists came from across the University bringing a diversity of experience, grounded in clinical governance, computing, and more traditional archiving. These examples are just a couple of the themes that we have covered so far in the forums, which have been derived predominantly from information provided by (and the needs of) the DCs themselves. Additional topics that we plan to cover in future forums include issues surrounding reproducibility, IP and commercialisation, publishing and the impact of research data.
Key aims of these forums are to not only facilitate networking between DCs but to also act as an arena for the transfer of knowledge along the ‘researcher pipeline’, from forum to DCs and from DCs to researchers in their departments.
DC specialisation group
As a community, we need to be able to map expertise internally and understand the make-up of such an organic group at any given moment. This makes it is easier to support each other and create collaborations, but also improves how we promote the programme externally.
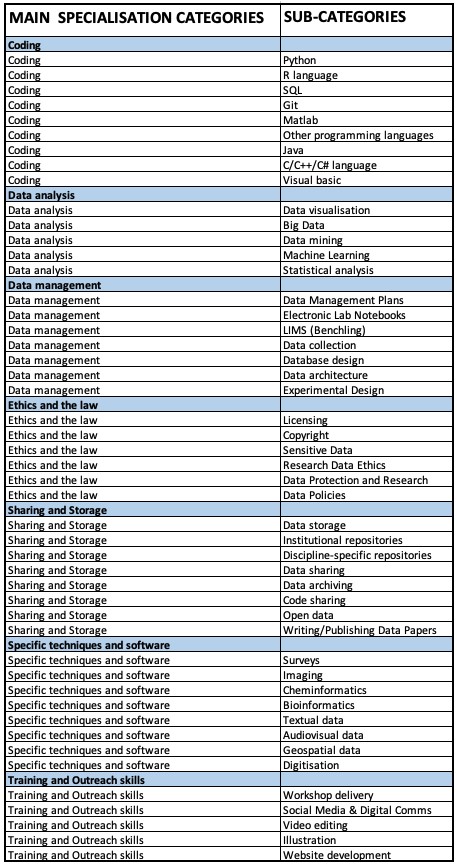
This led to the formation of the DC specialisation group, consisting of one of us and six of the DCs, which determined how to categorise expertise within the group. As a result, a spreadsheet was created where all DCs can chart their specialist areas and update or amend when necessary (and at least annually). We have top level categories for simple statistical analysis and second level categories that offer more specific details for the benefit of the DC community.
The next stage is to include the wider research community and improve how various stakeholders can reach the appropriate Data Champions for initial advice and support in RDM issues. One way to do this is by presenting more coherent and consistent specialisations on the Data Champions’ website, using the categories which we have already created for internal use within the group. This stage is due to begin this month and we hope to report on our efforts next year.
Branding group
A growing community is inevitably going to bring to the forefront various identity discussions. With this in mind, we formed a branding group to examine if a DC logo should be created to enhance the Data Champions’ visibility and raise their profile amongst their peers when advocating for RDM. A logo has been created and is going through various stages of approval before it will be released later this year.
Pilot programme – Mentoring
In February 2019, we initiated a pilot mentoring project as part of the induction process for the new DCs. The mentors are established DCs who have volunteered to support those new DCs wishing to take part in this pilot exercise. This followed on from our January forum where the benefits of mentoring for both mentees and mentors were outlined by Hannah Clements of RDP. At this forum, which preceded the University-wide call for new DCs, we also held a workshop where DCs were divided into three groups and asked three questions: what do you wish you knew when you first became a DC that you know now; what could you offer as mentors to the new DCs; how do you think the mentor-mentee system could work? The responses from DCs in the three groups informed the implementation, structure and aims of the mentoring pilot.
Our aim is to learn from this project in close consultation with both mentors and mentees. We want to see if this process helps new DCs to establish themselves within their departments/institutes. Will it be effective? The findings will inform our steps for the following year. Watch this space!
Fostering clusters within departments
We have excellent examples of departments that promote their DCs within their institutions. A good example is the Chemistry department, which has a cluster of five DCs who work together in their advocacy. During this year’s call for new DCs, and with help from the Department Librarian, we used a targeted approach at advertising the DC Programme within the Department of Engineering. This was highly successful, resulting in ten new Data Champions from Engineering from various roles and Academic Divisions. They represent a hub with the local knowledge, experience and skills to assess their department’s needs and explore best approaches to support good RDM practices and Open Research, ones that are tailored to the discipline.
Alumni community
Heading toward the programme’s third birthday means that we are growing bigger but also that we are developing an alumni community as well. This is a different kettle of fish but it is on our radar to investigate how we can foster this distinct group and build a network that is not only Cambridge based but has a more national and even international outlook.
Funding
Let’s not forget that the DC programme consists of volunteers. We are in the process of seeking more funds to support this ever increasing community, to run expanding bimonthly forums, and to be able to offer grants to assist DCs in their endeavours. As an example, we supported one of the DCs, James Savage, to bring the programme to the international stage in November at the SCIDataCon 2018 in Botswana. He talked about the programme as well as his experience of being a DC. This resulted in James writing a paper together with Lauren Cadwallader, to be published soon in Data Science Journal (the accepted manuscript and associated data available now in Apollo, the Cambridge University institutional repository).
An exciting year so far!
During this third year of the DC programme the number of active DCs across the University of Cambridge has doubled. We can only anticipate it growing further each year, yet balanced by an expanding community of alumni DCs as, for example, DCs leave Cambridge. The DC community is inherently dynamic, as is the programme. Because of this, we always seek to respond and adapt to changing conditions in novel and beneficial ways while maintaining the programme’s core structure to provide strong foundations. This has been a period of reflection, organisation and anticipation, all required to drive the Data Champion programme forward and tackle current challenges effectively, as well as those that lie ahead – more on this to come soon!
Written by Maria Angelaki and Dr Sacha Jones
Published 20 June 2019

