The Cambridge Data Champions had a fantastic September Forum at the West Hub. The forum started with an introduction to the West Hub by Library Manager Daniele Campello and we welcomed Clair Castle as the new interim Research Data Manager with the Office of Scholarly Communication (University Library).
Dr Mandy Wigdorowitz kicked off the presentations by sharing with the Data Champions what she aims to achieve as the University’s Open Research Community Manager. This includes raising the profile of Open Research at the University and ensuring that scholarly and research outputs that are deemed to be open are indeed accessible and interoperable in accordance with FAIR principles. As Open Research Community Manager, Mandy advocates for Open Research among University researchers from both the STEMM and AHSS (Art, Humanities and Social Sciences) disciplines. The latter proves to be more challenging as researchers in AHSS may often have valid reasons from refraining from making their research data open, such as working with sensitive data or working with interlocutors who object to their data being shared. Such issues will be addressed at the Cambridge Open Research Conference that she is organising, which takes place on 17th November 2023 at Downing College, Cambridge as well as online. To end, Mandy invited the Data Champions to join her Open Research initiative, a community of advocates for Open Research across the University.
Before lunch, Madeleine Taylor (Information Security Risk and Governance Manager with University Information Services, UIS) presented a follow up to a webinar session on monitoring the Information and Cybersecurity (ICS) risks for research data across the university, which she conducted with the Data Champions a couple weeks prior. After a brief introduction of what she has done so far to protect Cambridge’s research communities against ICS threats, she asked the Data Champions for help in her task of securing research data against ICS risks. They can do so by providing her with a sense of what data their own research communities are working with and how they were storing them. As the Data Champions ate the delicious lunch of sandwiches and cakes provided by the West Hub caterers, they provided feedback to Madeleine on two forms that she proposed as methods of gathering the information she needed: a 3-minute research data impact assessment form and a research data cyber security risk form. Maddy will continue to work with the Research Data Team and the Data Champions to refine, and gather information, through these forms.
Thank you to the West Hub and Daniele Campello for hosting the Data Champions Forum in your welcoming building!
If you are a member of the University of Cambridge and are interested in attending the Data Champions Forum, please join us as a Data Champion. If you are passionate about research data management and data sharing or you would like to find out more about what being a Data Champion entails, please visit the Data Champions webpage. We welcome applications from those working in all academic subjects across AHSS and STEMM disciplines. If you are unsure about how being a Data Champion would impact your research, please get in touch with the Research Data Team!
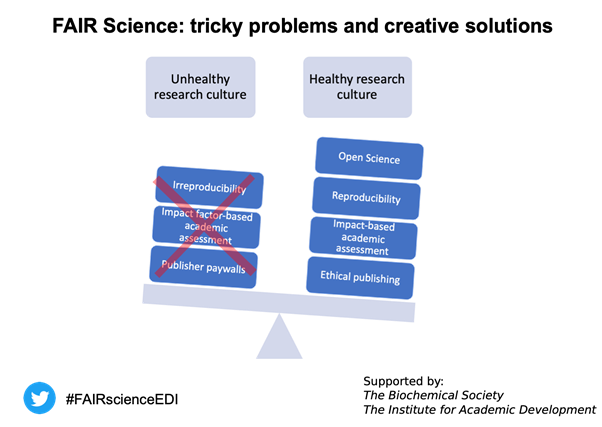
The Cambridge Data Champions are an example of a community of volunteers engaged in promoting open research and good research data management (RDM). Currently entering its third year, the programme has attracted a total of 127 volunteers (86 current, 41 alumni) from diverse disciplinary backgrounds and positions. It continues to grow and has inspired similar initiatives at other universities within and outside the UK (Madsen, 2019). Dr Sacha Jones, Research Data Coordinator at the Office of Scholarly Communication, recently shared information about the programme at ‘FAIR Science: tricky problems and creative solutions’, an Open Science event held on 4th June 2019 at The Queen’s Medical Research Institute in Edinburgh, and organised by a previous Cambridge Data Champion – Dr Ralitsa Madsen. The aim of this event was to disseminate information about Open Science and promote the subsequent set-up of a network of Edinburgh Open Research Champions, with inspiration from the Cambridge Data Champion programme. Running a Data Champion programme, however, is not free of challenges. In this blog, Sacha highlights some of these alongside potential solutions in the hope that this information may be helpful to others. In this vein, Ralitsa adds her insights from ‘FAIR Science’ in Edinburgh and discusses how similar local events may spearhead the development of additional Open Science programmes/networks, thus broadening the local reach of this movement in the UK and beyond.
#FAIRscienceEDI
On 4 June 2019, the University of Edinburgh hosted ‘FAIR Science: tricky problems and creative solutions’ – a one-day event that brought together local life scientists and research support staff to discuss systemic flaws within current academic culture as well as potential solutions. Funded by the Institute for Academic Development and the UK Biochemical Society, the event was popular – with around 100 attendees – featuring both students, postdocs, principal investigators (PIs) and administrative staff. The programme featured talks by a range of local researchers – Dr Ralitsa Madsen (postdoctoral fellow and event organiser), Dr William Cawthorn (junior PI), Prof Robert Semple (Dean of Postgraduate Research and senior PI), Prof Malcolm Macleod (senior PI and member of the UK Reproducibility Network steering group), Prof Andrew Millar (senior PI and Chief Scientific Advisor on Environment, Natural Resources and Agriculture, for Scottish Government), Aki MacFarlene (Wellcome Trust Open Research Programme Officer), Dr Naomi Penfold (Associate Director, ASAPbio), Dr Nigel Goddard and Rory Macneil (RSpace developers) and Robin Rice (Research Data Service, University of Edinburgh), and Dr Sacha Jones (University of Cambridge). All slides have been made available via the Open Science Framework, and “live” tweets can be found via #FAIRScienceEDI.
Shifting the balance of research culture for the better. Image source: Presentation by Ralitsa Madsen, ‘Why FAIR Science and why now?’
Why is open science important? What is the extent of the reproducibility problem in science, and what are the responsibilities of individual stakeholders? Do all researchers need to engage with open research? Are the right metrics used when assessing researchers for appointment, promotion and funding? What are the barriers to widespread change, and can they be overcome through collective efforts? These were some of the ‘tricky’ problems that were addressed during the first half of the ‘Fair Science’ event, with the second half focussing on ‘creative solutions’, including: abandoning the journal impact factor in favour of alternative and fairer assessment criteria such as those proposed in DORA; preprinting of scientific articles and pre-registration of individual studies; new incentives introduced by funders like the Wellcome Trust who seek to promote Open Science; and data management tools such as electronic lab notebooks. Finally, the event sought to inspire local efforts in Edinburgh to establish a volunteer-driven network of Open Research Champions by providing insight into the maturing Data Champion programme at the University of Cambridge. This was a popular ‘creative solution’, with more than 20 attendees providing their contact details to receive additional information about Open Science and the set-up of a local network.
Overall, community engagement was a recurring theme during the ‘FAIR Science’ event, recognised as a catalyst required for research culture to change direction toward open practices and better science. Robert Semple discussed this in the greatest detail, suggesting that early stage researchers – PhDs and post-docs – are the building blocks of such a community, supported also by senior academics who have a responsibility to use their positions (e.g. as group leaders, editors) to promote open science. “Open Science is a responsibility also of individual groups and scientists, and grass roots efforts will be key to culture shift” (Robert Semple’s presentation). On a larger scale, Aki MacFarlene aptly stated that a supportive research ecosystem is needed to support open research; for example, where institutions as well as funders recognise and reward open practices.
Insights from the Cambridge Data Champion programme
The Data Champions at the University of Cambridge are an example of a community and a source of support for others in the research ecosystem. Promoting good RDM and the FAIR principles are two fundamental goals that Data Champions commit to when they join the programme. For some, endorsing open research practices is a fortuitous by-product of being part of the programme, yet for others, this is a key motivation for joining.
This word cloud depicts the reasons why the Cambridge Data Champions applied to become a Data Champion (the larger the text size, the more common the response). It is based on data from 105 applicants responding to the following: “What is your main motivation for becoming a Data Champion?”
Now that the Data Champion programme has been running for three years, what challenges does it face, and might disclosing these here – alongside ongoing efforts to solve them – help others to establish and maintain similar initiatives elsewhere?
Four main challenges are outlined that the programme either has or continues to experience. These are discussed in increasing scale of difficulty to overcome.
Support
Retention
Disciplinary coverage
Measuring effectiveness
(See also a recent article about the Data Champion programme by James Savage and Lauren Cadwallader.)
What challenges does the Cambridge Data Champion programme face and how may these be overcome? (image: CC0)
Support
At a basic level, an initiative like the Data Champion programme needs both financial and institutional support. The Data Champions commit their time on a voluntary basis, yet the management of the programme, its regular events and occasional ad hoc projects all require funds. Currently, the programme is secure, but we continue to seek funding opportunities to support a community that is both expanding and deserving of reward (e.g. small grants awarded to Data Champions to support their ‘championing’ activities). Institutional support is already in place and hopefully this will continue to consolidate and grow now that the University has publicly committed to supporting open research.
Retention
Not all Data Champions who join will remain Data Champions. In fact, there is a growing community of alumni Data Champions. There are currently 41 alumni Data Champions. From the feedback provided by just over half of these, 68% left the programme because they left the University of Cambridge (as expected given that the majority of Data Champions are either post-docs or PhD students), and 32% left because of a lack of time to commit to the role. Of course, there might be other reasons that we are not aware of, and we cannot speculate here in the absence of data. Feedback from Data Champions is actively sought and is an essential part of sustaining and developing this type of community.
We are exploring various methods to enhance retention. To combat the pressures of individuals’ workloads, we are being transparent about the time that certain activities will involve – a task or process may be less overwhelming when a time estimate is provided (cf ‘this survey should take approximately ten minutes to complete’). We also initiated peer-mentoring amongst Data Champions this year, in part to encourage a stronger community. We are attempting to enhance networking within the community in other ways, during group discussion sessions in the bimonthly forums, and via a virtual space where Data Champions can view each other’s data-related specialisms – with mutual support and collaboration as intended by-products. These are just a few examples, and given that Data Champions are volunteers, retention is one of several aspects of the programme that requires frequent assessment.
Disciplinary coverage
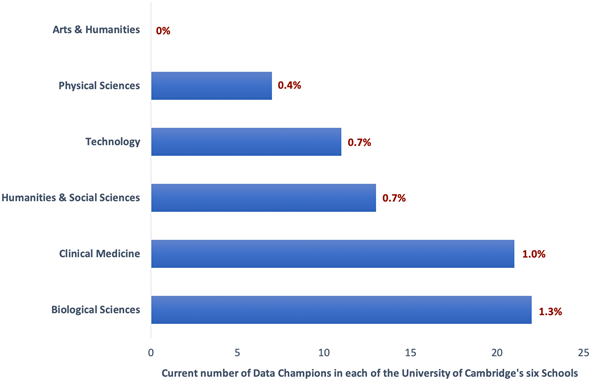
Cambridge has six Schools – Arts and Humanities, Humanities and Social Sciences, Biological Sciences, Physical Sciences, Clinical Medicine, and Technology – with faculties, departments, centres, units, institutes nested within these. The ideal situation would be for each research community (e.g. a department) to be supported by at least one Data Champion. Currently this is not the case, and the distribution of Data Champions across the different disciplinary areas is patchy. Biological Sciences is relatively well-represented by Data Champions (there are 22 Data Champions to represent around 1742 researchers in the School, i.e. 1.3%) (see bar chart below). There is a clear bias towards STEM (science, technology, engineering and maths) disciplines, yet representation in the social sciences is fair. At the more extreme end is an absence of Data Champions in the Arts and Humanities. We are looking to resolve this via a more targeted approach, guided in part by insights gained into researcher needs via the OSC’s training programme for arts, humanities and social sciences researchers.
The bars depict the number of Data Champions within each School. Percentage values give the number of Data Champions as a proportion of the total number of researchers within each School. For example, within the School of Clinical Medicine, the ratio of Data Champions to researchers is around 1:100 (researchers include contract and established researchers, and PhD students).
Measuring effectiveness
Determining how well the Data Champion programme is working is a sizeable challenge, as discussed previously. In those research communities represented by Data Champions, do we see improvements in data management, do we see a greater awareness of the FAIR principles, is there a change in research culture toward open research? These aspects are extremely difficult to measure and to assign to cause and effect, with multiple confounding factors to consider. We are working on how best to do this without overloading Data Champions and researchers with too many administrative tasks (e.g. surveys, questionnaires, etc.). Yet, the crux is for there to exist good communication and exchange of information between us (as a unit that is centrally managing the Data Champion programme) and the Data Champions, and between the Data Champions and the researchers who they are reaching out to and working with. We need to be the recipients of this information so that we can characterise the programme’s effectiveness and make improvements. As a start, the bimonthly Data Champion forums are used as an ideal venue to exchange and sound out ideas about best approaches, so that decisions on how to measure the programme’s impact lie also with the Data Champions.
A fifth challenge – recognition and reward
At the ‘FAIR Science’ event, two speakers (Naomi Penfold and Robert Semple) made a plea for those researchers who practise open science to be recognised for this – a change in reward culture is required. In a presentation centred on the misuse of metrics, Will Cawthorn referred to poor mental health in researchers as a result of the pressures of intrinsic but flawed methods of assessment. Understandably, DORA was mentioned multiple times at ‘FAIR Science’, and hopefully, with multiple universities including the University of Cambridge and University of Edinburgh as recent signatories of DORA, this marks the first steps toward a healthier and fairer researcher ecosystem. This may seem rather tangential to the Data Champions, but it is not: 66% of Data Champions, current and alumni, are or have been researchers (e.g. PhDs, post-docs, PIs). Despite the pressures of ‘publish or perish’, they have given precious time voluntarily to be a Data Champion and require recognition for this.
This raises a fifth challenge faced by the programme – how best to reward Data Champions for their contributions? Effectively addressing this may also help, via incentivisation, toward meeting three of the four challenges above – retention, coverage and measurement. While there is no official reward structure in place (see Higman et al. 2017), the benefits of being part of the programme are emphasised (networking opportunities, skills development, online presence as an expert, etc.), and we write to Heads of Departments so that Data Champions are recognised officially for their contributions. Is this enough? Perhaps not. We will address this issue via discussions at the September forum – how would those who are PhD students, post-docs, PIs, librarians, IT managers, data professionals (to name a few of the roles of Data Champions) like to be rewarded? In sharing these thoughts, we can then see what can be done.
Towards growing communities of volunteers
The Cambridge Data Champion programme is one among several UK- and Europe-wide initiatives that seek to promote good RDM and, more generally, Open Science. Their emergence speaks to a wider community interest and engagement in identifying solutions to some of the key issues haunting today’s academic culture (Madsen 2019). While the foundations of a network of Edinburgh Open Research Champions are still being laid, TU Delft in the Netherlands has already got their Data Champion programme up and running with inspiration from Cambridge. Independently, several Universities in the UK have also established their own Open Research groups, many of which are joined together through the recently established UK Reproducibility Network (UKRN) and the associated UK Network of Open Research Working Groups (UK-ORWG). Such integration fosters network crosstalk and is a step in the right direction, giving volunteers a stronger sense of ‘belonging’ while also actively working towards their formal recognition. Network crosstalk allows for beneficial resource sharing through centralised platforms such as the Open Science Framework or through direct knowledge exchange among neighbouring institutions. Following ‘FAIR Science’ in Edinburgh, for example, a meeting to discuss its outcome(s) involved members from Glasgow University’s Library Services (Valerie McCutcheon, Research Information Manager) and the UKRN’s local lead at Aberdeen University (Dr Jessica Butler, Research Fellow, Institute of Applied Health Science). Thus, similar to plans in Aberdeen, the ‘FAIR Science’ organisers are currently working with Edinburgh University’s Research Data Support team to adapt an Open Science survey developed and used at Cardiff University to guide the development of a specific Open Science strategy. This reflects the critical requirements for such strategies to be successful – active peer-to-peer engagement and community involvement to ensure that any initiatives match the needs of those who ought to benefit from them.
The long-term success of Open Science strategies – and any associated networks – will also hinge upon incorporation of formal recognition, as alluded to in the context of the Cambridge Data Champion programme. The importance of formal recognition of Open Science volunteers is also exemplified in SPARC Europe’s recent initiative – Europe’s Open Data Champions – which aims to showcase Open Data leaders who help ‘to change the hearts and minds of their peers towards more Openness’.
For formal recognition to gain traction, it will be critical to work towards recruitment of several prominent senior academics on board the Open Science wagon. By virtue of their academic status, such individuals will be able to put Open Science credentials high on the agenda of funding and academic institutions. Indeed, the establishment of the UKRN can be ascribed to a handful of senior researchers who have been able to secure financial support for this initiative, in addition to inspiring and nucleating local engagement across several UK universities. The ‘FAIR Science’ experience in Edinburgh supports this view. While difficult to prove, its impact would likely have been minimal without the involvement of prominent senior academics, including Professor Robert Semple (Dean of Postgraduate Research), Professor Malcolm Macleod (UKRN steering group member) and Professor Andrew Millar (Chief Scientific Advisor on Environment, Natural Resources and Agriculture, for Scottish Government). Thus, in addition to targeted and continuous communication by the ‘FAIR Science’ organisers before and after the event, ongoing efforts to establish a network of Edinburgh Open Research Champions has been dependent on these senior academics and their ability to mobilise essential forces throughout the University of Edinburgh.
Amongst several other factors, community engagement is central to making improvements toward reproducibility, Open Science and Open Research in general. There are multiple stakeholders involved with their own responsibilities, and senior academics are a notable part of this. Image source: Robert Semple’s presentation at #FAIRscienceEdi, ‘The “Reproducibility Crisis”: lessons learnt on the job’.
Top-down or bottom-up?
Establishing and maintaining a champions initiative need not be conceived of as succeeding via either a top-down or bottom-up approach. Instead, a combination of the best of both of these approaches is optimal, as hopefully comes across here. The emphasis on such initiatives being community driven is essential, yet structure is also required so as to ensure their maintenance and longevity. Hierarchies have little place in such communities – there are enough of these already in the ‘researcher ecosystem’ – and the beauty of such initiatives is that they bring together people from various contexts (e.g. in terms of role, discipline, institution). In this sense, the Cambridge Data Champions community is especially robust because of its diversity, being comprised of individuals who derive from highly varied roles and disciplinary backgrounds. Every champion brings their own individual strengths; collectively, this is a powerful resource in terms of knowledge and skills. Through acting on these strengths and acknowledging their responsibilities (e.g. to influence, teach, engage others), and by being part of a community like those described here, champions have the opportunity to make perhaps a wider contribution to research than ever anticipated, and certainly one that enhances its overall integrity.
References
Higman, R., Teperek, M. & Kingsley, D. (2017). Creating a community of Data Champions. International Journal of Digital Curation 12 (2): 96–106. DOI: https://doi.org/10.2218/ijdc.v12i2.562
Savage, J. & Cadwallader, L. (2019). Establishing, Developing, and Sustaining a Community of Data Champions. Data Science Journal 18 (23): 1–8. DOI: https://doi.org/10.5334/dsj-2019-023
The Cambridge Data Champions (DCs) advocate good Research Data Management (RDM) and Open Data practices to researchers locally in their departments, within Cambridge University in general, and sometimes further afield. They network with one another, exchange good methods of RDM, share ideas and, as a collective, reflect on current issues surrounding RDM, Open Data and researcher engagement, where a major shared goal is to establish best practices when it comes to research data. By attending bi-monthly forums facilitated by the Research Data Team, the DCs convene as a community, hear speakers presenting on relevant topics, and engage in workshops that will help them in their ‘championing’ activities. Following up from our latest blog which summarised how a workshop led to the creation of cartoon postcards as a new tool to add to the DCs’ resource kit for RDM advocacy, we are now reflecting on initiatives that sprung from workshops during the past year and are considering the challenges and opportunities that this programme brings as it approaches the end of its third year.
Growing
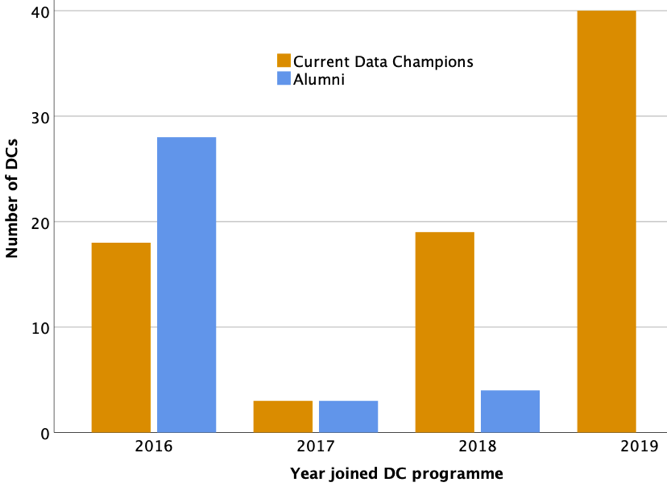
The programme started in Autumn 2016, comprising researchers who volunteered to become local community experts and advocate on research data management and sharing. Our first call welcomed 43 DCs (September 2016), our second call 20 DCs (March 2018) and the third call 40 DCs (January 2019). For simplicity, this year we also added to our statistics the “affiliate” DCs, who are colleagues who contribute to the DC community in other ways (as interested members of Cambridge’s RDM Project Group) and not necessarily through channelling their RDM efforts for the benefit of a specific department.
We are now a community comprised of 87 active DCs.
Total number of Data Champions who joined in each year (orange column indicates Champions who are still active; blue column indicates Champions who are now alumni).
Communities within a community
Over the last year we caught ourselves using words such as the ‘old DCs’ and the ‘new DCs’ and what we really meant was ‘established DCs’ and ‘new DCs’, with the latter group being those joining the programme each year. In September we celebrate the programme’s third birthday and it is reasonable to expect that there will be more experienced DCs who have already built their networks and have, more or less, a stable offering of RDM support and an enhanced understanding of the needs of their department. On the other hand, there are those who are being welcomed into the group who seek, to differing degrees, initial support from both the RDM team and their fellow colleagues in order to become successful DCs. It is easy to imagine that different layers are being developed with different needs, both in terms of support and engagement.
Through various activities and feedback from DCs, we now have a good quantity of raw data to analyse their needs for being, as we called it, ‘a good Data Champion’. We have brainstormed ideas which we are putting into action to respond to the challenges of an ever-growing Data Champions group.
Planning
DC Welcome Pack
Every year we circulate the Data Champions Welcome Pack to coincide with the inductions we organise to welcome new DCs into the group. This year we included in the pack what it is expected from a DC when s/he joins the programme so that expectations are clearly communicated from the beginning and are the same for everybody.
Page from the Cambridge Data Champions Welcome Pack
Bi-monthly forums
Lightning talks have been introduced as a standard item in each forum. These have provided DCs with the opportunity to discuss aspects of RDM they are working on (e.g. new tools and techniques), or to feed back to the group on DC activities undertaken in their departments and data-related events they have attended so that the whole group can benefit. Importantly, the lightning talks have been used by DCs to problem solve, where the collective knowledge and experience of DCs attending a forum has been harnessed to address particular challenges faced by individual DCs. This is where the community aspect of the programme truly shines.
It is always a priority for us to invite speakers to forums who are external to the programme, reflecting the needs of both the new and established DCs. For example, Hannah Clements from Cambridge University’s Researcher Development Programme (RDP) spoke to the DCs at the January forum about mentoring, providing guidance on how support can be best delivered within the DC community. In the May forum, we had talks and discussions from a panel of experts working on different aspects of data archiving. The panellists came from across the University bringing a diversity of experience, grounded in clinical governance, computing, and more traditional archiving. These examples are just a couple of the themes that we have covered so far in the forums, which have been derived predominantly from information provided by (and the needs of) the DCs themselves. Additional topics that we plan to cover in future forums include issues surrounding reproducibility, IP and commercialisation, publishing and the impact of research data.
Key aims of these forums are to not only facilitate networking between DCs but to also act as an arena for the transfer of knowledge along the ‘researcher pipeline’, from forum to DCs and from DCs to researchers in their departments.
DCspecialisation group
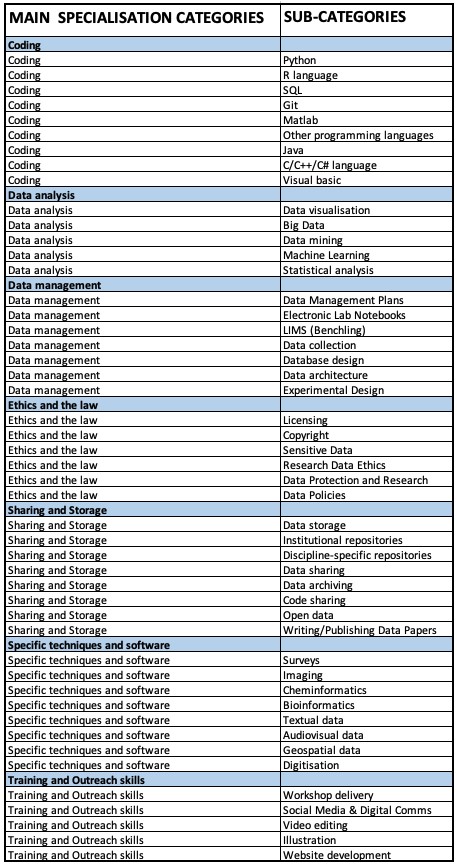
As a community, we need to be able to map expertise internally and understand the make-up of such an organic group at any given moment. This makes it is easier to support each other and create collaborations, but also improves how we promote the programme externally.
Areas of expertise amongst our Data Champions
This led to the formation of the DC specialisation group, consisting of one of us and six of the DCs, which determined how to categorise expertise within the group. As a result, a spreadsheet was created where all DCs can chart their specialist areas and update or amend when necessary (and at least annually). We have top level categories for simple statistical analysis and second level categories that offer more specific details for the benefit of the DC community.
The next stage is to include the wider research community and improve how various stakeholders can reach the appropriate Data Champions for initial advice and support in RDM issues. One way to do this is by presenting more coherent and consistent specialisations on the Data Champions’ website, using the categories which we have already created for internal use within the group. This stage is due to begin this month and we hope to report on our efforts next year.
Branding group
A growing community is inevitably going to bring to the forefront various identity discussions. With this in mind, we formed a branding group to examine if a DC logo should be created to enhance the Data Champions’ visibility and raise their profile amongst their peers when advocating for RDM. A logo has been created and is going through various stages of approval before it will be released later this year.
Pilot programme – Mentoring
In February 2019, we initiated a pilot mentoring project as part of the induction process for the new DCs. The mentors are established DCs who have volunteered to support those new DCs wishing to take part in this pilot exercise. This followed on from our January forum where the benefits of mentoring for both mentees and mentors were outlined by Hannah Clements of RDP. At this forum, which preceded the University-wide call for new DCs, we also held a workshop where DCs were divided into three groups and asked three questions: what do you wish you knew when you first became a DC that you know now; what could you offer as mentors to the new DCs; how do you think the mentor-mentee system could work? The responses from DCs in the three groups informed the implementation, structure and aims of the mentoring pilot.
Our aim is to learn from this project in close consultation with both mentors and mentees. We want to see if this process helps new DCs to establish themselves within their departments/institutes. Will it be effective? The findings will inform our steps for the following year. Watch this space!
Fostering clusters within departments
We have excellent examples of departments that promote their DCs within their institutions. A good example is the Chemistry department, which has a cluster of five DCs who work together in their advocacy. During this year’s call for new DCs, and with help from the Department Librarian, we used a targeted approach at advertising the DC Programme within the Department of Engineering. This was highly successful, resulting in ten new Data Champions from Engineering from various roles and Academic Divisions. They represent a hub with the local knowledge, experience and skills to assess their department’s needs and explore best approaches to support good RDM practices and Open Research, ones that are tailored to the discipline.
Alumni community
Heading toward the programme’s third birthday means that we are growing bigger but also that we are developing an alumni community as well. This is a different kettle of fish but it is on our radar to investigate how we can foster this distinct group and build a network that is not only Cambridge based but has a more national and even international outlook.
Funding
Let’s not forget that the DC programme consists of volunteers. We are in the process of seeking more funds to support this ever increasing community, to run expanding bimonthly forums, and to be able to offer grants to assist DCs in their endeavours. As an example, we supported one of the DCs, James Savage, to bring the programme to the international stage in November at the SCIDataCon 2018 in Botswana. He talked about the programme as well as his experience of being a DC. This resulted in James writing a paper together with Lauren Cadwallader, to be published soon in Data Science Journal (the accepted manuscript and associated data available now in Apollo, the Cambridge University institutional repository).
An exciting year so far!
During this third year of the DC programme the number of active DCs across the University of Cambridge has doubled. We can only anticipate it growing further each year, yet balanced by an expanding community of alumni DCs as, for example, DCs leave Cambridge. The DC community is inherently dynamic, as is the programme. Because of this, we always seek to respond and adapt to changing conditions in novel and beneficial ways while maintaining the programme’s core structure to provide strong foundations. This has been a period of reflection, organisation and anticipation, all required to drive the Data Champion programme forward and tackle current challenges effectively, as well as those that lie ahead – more on this to come soon!
Written by Maria Angelaki and Dr Sacha Jones
Published 20 June 2019
Your cookie choices
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behaviour or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.