This year we have continued, as always, to provide support and services for researchers to help with their research data management and open data practices. So far in 2020, we have approved more than 230 datasets into our institutional repository, Apollo. This includes Apollo’s 2000th dataset on the impact of health warning labels on snack selection, which represents a shining example of reproducible research, involving the full gamut: preregistration, and sharing of consent forms, code, protocols, data. There are other studies that have sparked media interest for which the data are also openly available in Apollo, such as the data supporting research that reports the development of a wireless device that can convert sunlight, carbon dioxide and water into a carbon-neutral fuel. Or, data supporting a study that has used computational modelling to explain why blues and greens are the brightest colours in nature. Also, and in the year of COVID, a dataset was published in April on the ability of common fabrics to filter ultrafine particles, associated with an article in BMJ Open. Sharing data associated with publications is critical for the integrity of many disciplines and best practice in the majority of studies, but there is also an important responsibility of science communication in particular to bring research datasets to the forefront. This point was discussed eloquently this summer in a guest blog post in Unlocking Research by Itamar Shatz, a researcher and Cambridge Data Champion. Making datasets open permits their reuse, and if you have wondered how research data is reused and then read this comprehensive data sharing and reuse case study written by the Research Data team’s Dominic Dixon. This centres on the use and value of the Mammographic Image Society database, published in Apollo five years ago.
This year has seen the necessary move from our usual face-to-face Research Data Management (RDM) training to provision of training online. This has led us to produce an online training session in RDM, covering topics such as data organisation, storage, back up and sharing, as well as data management plans. This forms one component of a broader Research Skills Guide – an online course for Cambridge researchers on publishing, managing data, finding and disseminating research – developed by Dr Bea Gini, the OSC’s training coordinator. We have also contributed to a ‘Managing your study resources’ CamGuide for Master’s students, providing guidance on how to work reproducibly. In collaboration with several University stakeholders we released last month new guidance on the use of electronic research notebooks (ERNs), providing information on the features of ERNs and guidance to help researchers select one that is suitable.
At the start of this year we invited members of the University to apply to become Data Champions, joining the pre-existing community of 72 Data Champions. The 2020 call was very successful, with us welcoming 56 new Data Champions to the programme. The community has expanded this year, not only in terms of numbers of volunteers but also in terms of disciplinary focus, where there are now Data Champions in several areas of the arts, humanities and social sciences in particular where there were none previously. During this year, we have held forums in person and then online, covering themes such as how to curate manual research records, ideas for RDM guidance materials, data management in the time of coronavirus, and data practices in the arts and humanities and how these can be best supported. We look forward to further supporting and advocating the fantastic work of the Cambridge Data Champions in the months and years to come.
The Cambridge Data Champions are an example of a community of volunteers engaged in promoting open research and good research data management (RDM). Currently entering its third year, the programme has attracted a total of 127 volunteers (86 current, 41 alumni) from diverse disciplinary backgrounds and positions. It continues to grow and has inspired similar initiatives at other universities within and outside the UK (Madsen, 2019). Dr Sacha Jones, Research Data Coordinator at the Office of Scholarly Communication, recently shared information about the programme at ‘FAIR Science: tricky problems and creative solutions’, an Open Science event held on 4th June 2019 at The Queen’s Medical Research Institute in Edinburgh, and organised by a previous Cambridge Data Champion – Dr Ralitsa Madsen. The aim of this event was to disseminate information about Open Science and promote the subsequent set-up of a network of Edinburgh Open Research Champions, with inspiration from the Cambridge Data Champion programme. Running a Data Champion programme, however, is not free of challenges. In this blog, Sacha highlights some of these alongside potential solutions in the hope that this information may be helpful to others. In this vein, Ralitsa adds her insights from ‘FAIR Science’ in Edinburgh and discusses how similar local events may spearhead the development of additional Open Science programmes/networks, thus broadening the local reach of this movement in the UK and beyond.
#FAIRscienceEDI
On 4 June 2019, the University of Edinburgh hosted ‘FAIR Science: tricky problems and creative solutions’ – a one-day event that brought together local life scientists and research support staff to discuss systemic flaws within current academic culture as well as potential solutions. Funded by the Institute for Academic Development and the UK Biochemical Society, the event was popular – with around 100 attendees – featuring both students, postdocs, principal investigators (PIs) and administrative staff. The programme featured talks by a range of local researchers – Dr Ralitsa Madsen (postdoctoral fellow and event organiser), Dr William Cawthorn (junior PI), Prof Robert Semple (Dean of Postgraduate Research and senior PI), Prof Malcolm Macleod (senior PI and member of the UK Reproducibility Network steering group), Prof Andrew Millar (senior PI and Chief Scientific Advisor on Environment, Natural Resources and Agriculture, for Scottish Government), Aki MacFarlene (Wellcome Trust Open Research Programme Officer), Dr Naomi Penfold (Associate Director, ASAPbio), Dr Nigel Goddard and Rory Macneil (RSpace developers) and Robin Rice (Research Data Service, University of Edinburgh), and Dr Sacha Jones (University of Cambridge). All slides have been made available via the Open Science Framework, and “live” tweets can be found via #FAIRScienceEDI.
Shifting the balance of research culture for the better. Image source: Presentation by Ralitsa Madsen, ‘Why FAIR Science and why now?’
Why is open science important? What is the extent of the reproducibility problem in science, and what are the responsibilities of individual stakeholders? Do all researchers need to engage with open research? Are the right metrics used when assessing researchers for appointment, promotion and funding? What are the barriers to widespread change, and can they be overcome through collective efforts? These were some of the ‘tricky’ problems that were addressed during the first half of the ‘Fair Science’ event, with the second half focussing on ‘creative solutions’, including: abandoning the journal impact factor in favour of alternative and fairer assessment criteria such as those proposed in DORA; preprinting of scientific articles and pre-registration of individual studies; new incentives introduced by funders like the Wellcome Trust who seek to promote Open Science; and data management tools such as electronic lab notebooks. Finally, the event sought to inspire local efforts in Edinburgh to establish a volunteer-driven network of Open Research Champions by providing insight into the maturing Data Champion programme at the University of Cambridge. This was a popular ‘creative solution’, with more than 20 attendees providing their contact details to receive additional information about Open Science and the set-up of a local network.
Overall, community engagement was a recurring theme during the ‘FAIR Science’ event, recognised as a catalyst required for research culture to change direction toward open practices and better science. Robert Semple discussed this in the greatest detail, suggesting that early stage researchers – PhDs and post-docs – are the building blocks of such a community, supported also by senior academics who have a responsibility to use their positions (e.g. as group leaders, editors) to promote open science. “Open Science is a responsibility also of individual groups and scientists, and grass roots efforts will be key to culture shift” (Robert Semple’s presentation). On a larger scale, Aki MacFarlene aptly stated that a supportive research ecosystem is needed to support open research; for example, where institutions as well as funders recognise and reward open practices.
Insights from the Cambridge Data Champion programme
The Data Champions at the University of Cambridge are an example of a community and a source of support for others in the research ecosystem. Promoting good RDM and the FAIR principles are two fundamental goals that Data Champions commit to when they join the programme. For some, endorsing open research practices is a fortuitous by-product of being part of the programme, yet for others, this is a key motivation for joining.
This word cloud depicts the reasons why the Cambridge Data Champions applied to become a Data Champion (the larger the text size, the more common the response). It is based on data from 105 applicants responding to the following: “What is your main motivation for becoming a Data Champion?”
Now that the Data Champion programme has been running for three years, what challenges does it face, and might disclosing these here – alongside ongoing efforts to solve them – help others to establish and maintain similar initiatives elsewhere?
Four main challenges are outlined that the programme either has or continues to experience. These are discussed in increasing scale of difficulty to overcome.
Support
Retention
Disciplinary coverage
Measuring effectiveness
(See also a recent article about the Data Champion programme by James Savage and Lauren Cadwallader.)
What challenges does the Cambridge Data Champion programme face and how may these be overcome? (image: CC0)
Support
At a basic level, an initiative like the Data Champion programme needs both financial and institutional support. The Data Champions commit their time on a voluntary basis, yet the management of the programme, its regular events and occasional ad hoc projects all require funds. Currently, the programme is secure, but we continue to seek funding opportunities to support a community that is both expanding and deserving of reward (e.g. small grants awarded to Data Champions to support their ‘championing’ activities). Institutional support is already in place and hopefully this will continue to consolidate and grow now that the University has publicly committed to supporting open research.
Retention
Not all Data Champions who join will remain Data Champions. In fact, there is a growing community of alumni Data Champions. There are currently 41 alumni Data Champions. From the feedback provided by just over half of these, 68% left the programme because they left the University of Cambridge (as expected given that the majority of Data Champions are either post-docs or PhD students), and 32% left because of a lack of time to commit to the role. Of course, there might be other reasons that we are not aware of, and we cannot speculate here in the absence of data. Feedback from Data Champions is actively sought and is an essential part of sustaining and developing this type of community.
We are exploring various methods to enhance retention. To combat the pressures of individuals’ workloads, we are being transparent about the time that certain activities will involve – a task or process may be less overwhelming when a time estimate is provided (cf ‘this survey should take approximately ten minutes to complete’). We also initiated peer-mentoring amongst Data Champions this year, in part to encourage a stronger community. We are attempting to enhance networking within the community in other ways, during group discussion sessions in the bimonthly forums, and via a virtual space where Data Champions can view each other’s data-related specialisms – with mutual support and collaboration as intended by-products. These are just a few examples, and given that Data Champions are volunteers, retention is one of several aspects of the programme that requires frequent assessment.
Disciplinary coverage
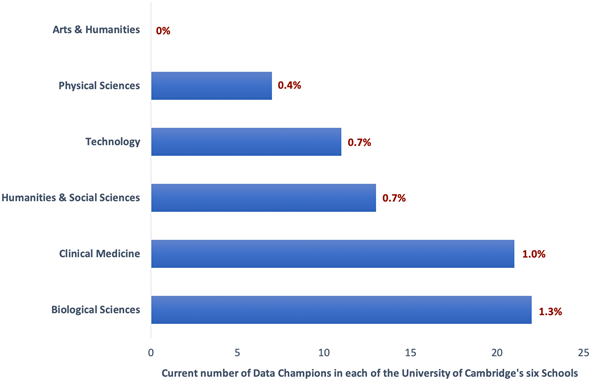
Cambridge has six Schools – Arts and Humanities, Humanities and Social Sciences, Biological Sciences, Physical Sciences, Clinical Medicine, and Technology – with faculties, departments, centres, units, institutes nested within these. The ideal situation would be for each research community (e.g. a department) to be supported by at least one Data Champion. Currently this is not the case, and the distribution of Data Champions across the different disciplinary areas is patchy. Biological Sciences is relatively well-represented by Data Champions (there are 22 Data Champions to represent around 1742 researchers in the School, i.e. 1.3%) (see bar chart below). There is a clear bias towards STEM (science, technology, engineering and maths) disciplines, yet representation in the social sciences is fair. At the more extreme end is an absence of Data Champions in the Arts and Humanities. We are looking to resolve this via a more targeted approach, guided in part by insights gained into researcher needs via the OSC’s training programme for arts, humanities and social sciences researchers.
The bars depict the number of Data Champions within each School. Percentage values give the number of Data Champions as a proportion of the total number of researchers within each School. For example, within the School of Clinical Medicine, the ratio of Data Champions to researchers is around 1:100 (researchers include contract and established researchers, and PhD students).
Measuring effectiveness
Determining how well the Data Champion programme is working is a sizeable challenge, as discussed previously. In those research communities represented by Data Champions, do we see improvements in data management, do we see a greater awareness of the FAIR principles, is there a change in research culture toward open research? These aspects are extremely difficult to measure and to assign to cause and effect, with multiple confounding factors to consider. We are working on how best to do this without overloading Data Champions and researchers with too many administrative tasks (e.g. surveys, questionnaires, etc.). Yet, the crux is for there to exist good communication and exchange of information between us (as a unit that is centrally managing the Data Champion programme) and the Data Champions, and between the Data Champions and the researchers who they are reaching out to and working with. We need to be the recipients of this information so that we can characterise the programme’s effectiveness and make improvements. As a start, the bimonthly Data Champion forums are used as an ideal venue to exchange and sound out ideas about best approaches, so that decisions on how to measure the programme’s impact lie also with the Data Champions.
A fifth challenge – recognition and reward
At the ‘FAIR Science’ event, two speakers (Naomi Penfold and Robert Semple) made a plea for those researchers who practise open science to be recognised for this – a change in reward culture is required. In a presentation centred on the misuse of metrics, Will Cawthorn referred to poor mental health in researchers as a result of the pressures of intrinsic but flawed methods of assessment. Understandably, DORA was mentioned multiple times at ‘FAIR Science’, and hopefully, with multiple universities including the University of Cambridge and University of Edinburgh as recent signatories of DORA, this marks the first steps toward a healthier and fairer researcher ecosystem. This may seem rather tangential to the Data Champions, but it is not: 66% of Data Champions, current and alumni, are or have been researchers (e.g. PhDs, post-docs, PIs). Despite the pressures of ‘publish or perish’, they have given precious time voluntarily to be a Data Champion and require recognition for this.
This raises a fifth challenge faced by the programme – how best to reward Data Champions for their contributions? Effectively addressing this may also help, via incentivisation, toward meeting three of the four challenges above – retention, coverage and measurement. While there is no official reward structure in place (see Higman et al. 2017), the benefits of being part of the programme are emphasised (networking opportunities, skills development, online presence as an expert, etc.), and we write to Heads of Departments so that Data Champions are recognised officially for their contributions. Is this enough? Perhaps not. We will address this issue via discussions at the September forum – how would those who are PhD students, post-docs, PIs, librarians, IT managers, data professionals (to name a few of the roles of Data Champions) like to be rewarded? In sharing these thoughts, we can then see what can be done.
Towards growing communities of volunteers
The Cambridge Data Champion programme is one among several UK- and Europe-wide initiatives that seek to promote good RDM and, more generally, Open Science. Their emergence speaks to a wider community interest and engagement in identifying solutions to some of the key issues haunting today’s academic culture (Madsen 2019). While the foundations of a network of Edinburgh Open Research Champions are still being laid, TU Delft in the Netherlands has already got their Data Champion programme up and running with inspiration from Cambridge. Independently, several Universities in the UK have also established their own Open Research groups, many of which are joined together through the recently established UK Reproducibility Network (UKRN) and the associated UK Network of Open Research Working Groups (UK-ORWG). Such integration fosters network crosstalk and is a step in the right direction, giving volunteers a stronger sense of ‘belonging’ while also actively working towards their formal recognition. Network crosstalk allows for beneficial resource sharing through centralised platforms such as the Open Science Framework or through direct knowledge exchange among neighbouring institutions. Following ‘FAIR Science’ in Edinburgh, for example, a meeting to discuss its outcome(s) involved members from Glasgow University’s Library Services (Valerie McCutcheon, Research Information Manager) and the UKRN’s local lead at Aberdeen University (Dr Jessica Butler, Research Fellow, Institute of Applied Health Science). Thus, similar to plans in Aberdeen, the ‘FAIR Science’ organisers are currently working with Edinburgh University’s Research Data Support team to adapt an Open Science survey developed and used at Cardiff University to guide the development of a specific Open Science strategy. This reflects the critical requirements for such strategies to be successful – active peer-to-peer engagement and community involvement to ensure that any initiatives match the needs of those who ought to benefit from them.
The long-term success of Open Science strategies – and any associated networks – will also hinge upon incorporation of formal recognition, as alluded to in the context of the Cambridge Data Champion programme. The importance of formal recognition of Open Science volunteers is also exemplified in SPARC Europe’s recent initiative – Europe’s Open Data Champions – which aims to showcase Open Data leaders who help ‘to change the hearts and minds of their peers towards more Openness’.
For formal recognition to gain traction, it will be critical to work towards recruitment of several prominent senior academics on board the Open Science wagon. By virtue of their academic status, such individuals will be able to put Open Science credentials high on the agenda of funding and academic institutions. Indeed, the establishment of the UKRN can be ascribed to a handful of senior researchers who have been able to secure financial support for this initiative, in addition to inspiring and nucleating local engagement across several UK universities. The ‘FAIR Science’ experience in Edinburgh supports this view. While difficult to prove, its impact would likely have been minimal without the involvement of prominent senior academics, including Professor Robert Semple (Dean of Postgraduate Research), Professor Malcolm Macleod (UKRN steering group member) and Professor Andrew Millar (Chief Scientific Advisor on Environment, Natural Resources and Agriculture, for Scottish Government). Thus, in addition to targeted and continuous communication by the ‘FAIR Science’ organisers before and after the event, ongoing efforts to establish a network of Edinburgh Open Research Champions has been dependent on these senior academics and their ability to mobilise essential forces throughout the University of Edinburgh.
Amongst several other factors, community engagement is central to making improvements toward reproducibility, Open Science and Open Research in general. There are multiple stakeholders involved with their own responsibilities, and senior academics are a notable part of this. Image source: Robert Semple’s presentation at #FAIRscienceEdi, ‘The “Reproducibility Crisis”: lessons learnt on the job’.
Top-down or bottom-up?
Establishing and maintaining a champions initiative need not be conceived of as succeeding via either a top-down or bottom-up approach. Instead, a combination of the best of both of these approaches is optimal, as hopefully comes across here. The emphasis on such initiatives being community driven is essential, yet structure is also required so as to ensure their maintenance and longevity. Hierarchies have little place in such communities – there are enough of these already in the ‘researcher ecosystem’ – and the beauty of such initiatives is that they bring together people from various contexts (e.g. in terms of role, discipline, institution). In this sense, the Cambridge Data Champions community is especially robust because of its diversity, being comprised of individuals who derive from highly varied roles and disciplinary backgrounds. Every champion brings their own individual strengths; collectively, this is a powerful resource in terms of knowledge and skills. Through acting on these strengths and acknowledging their responsibilities (e.g. to influence, teach, engage others), and by being part of a community like those described here, champions have the opportunity to make perhaps a wider contribution to research than ever anticipated, and certainly one that enhances its overall integrity.
References
Higman, R., Teperek, M. & Kingsley, D. (2017). Creating a community of Data Champions. International Journal of Digital Curation 12 (2): 96–106. DOI: https://doi.org/10.2218/ijdc.v12i2.562
Savage, J. & Cadwallader, L. (2019). Establishing, Developing, and Sustaining a Community of Data Champions. Data Science Journal 18 (23): 1–8. DOI: https://doi.org/10.5334/dsj-2019-023
In July 2017, the Wellcome Trust updated their policy on the management and sharing of research outputs.This policy helps deliver Wellcome’s mission – to improve health for everyone by enabling great ideas to thrive. The University of Cambridge’s Research Data Management Facility invited Wellcome Trust to Cambridge to talk with their funded research community (and potential researchers) about what this updated policy means for them. On 5th December in the Gurdon Institute Tea Room, the Deputy Head of Scholarly Communication Dr Lauren Cadwallader, welcomed Robert Kiley, Head of Open Research, and David Carr, Open Research Programme Manager, from the Wellcome’s Open Research Team.
This blog summarises the presentations from David and Robert about the research outputs policy and how it has been working and the questions raised by the audience.
Maximising the value of research outputs: Wellcome’s approach
David Carr outlined key points about the new policy, which now, in addition to sharing openly publications and data, includes sharing software and materials as other valued outputs of research.
An outputs management plan is required to show how the outputs of the project will be managed and the value of the outputs maximised (whilst taking into consideration that not all outputs can be shared openly). Updated guidance on outputs management plans has been published and can be found on Wellcome’s website.
Researchers are also to note that:
Outputs should be made available with as few restrictions as possible.
Data and software underlying publications must be made available at the time of publication at the latest.
Data relevant to a public health emergency should be shared as soon as it has been quality assured regardless of publication timelines.
Outputs should be placed in community repositories, have persistent identifiers and be discoverable.
A check at the final report stage, to ensure outputs have been shared according to the policy, has been introduced (recognising that parameters change during the research and management plans can change accordingly).
Of course, management and sharing of research outputs comes with a cost and Wellcome Trust commit to reviewing and supporting associated costs as part of the grant.
Wellcome have periodically reviewed take-up and implementation of their research outputs sharing and management policy and have observed some key responses:
Researchers are producing better quality plans; however, the formats and level of detail included in the plans do remain variable.
There is uncertainty amongst stakeholders (researchers, reviewers and institutions) in how to fulfil the policy.
Resources required to deliver plans are often not fully considered or requested.
Follow-up and reporting about compliance has been patchy.
In response to these findings, Wellcome will continue to update their guidance and work with their communities to advise, educate and define best practice. They will encourage researchers to work more closely with their institutions, particularly over resource planning. They will also develop a proportionate mechanism to monitor compliance.
Developing Open Research
Robert Kiley then described the three areas which the dedicated Open Research Team at Wellcome lead and coordinate: funder-led activities; community-led activities and policy leadership.
Funder-led activities include:
Wellcome Open Research, the publishing platform launched in partnership with F1000 around a year ago; here Wellcome-funded researchers can rapidly and transparently publish any results they think are worth sharing. Average submission to publication time for the first 100 papers published was 72 days – much faster than other publication venues.
Wellcome Trust is working with ASAP-Bio and other funders to support pre-prints and continues to support e-Life as an innovative Open Access journal.
Wellcome Trust will review their Open Access policy during 2018 and will consult their funded researchers and institutions as part of this process.
Wellcome provides the secretariat for the independent review panel for the com (CSDR) platform which provides access to anonymised clinical trial data from 13 pharmaceutical companies. From January 2018, they will extend the resource to allow listing of academic clinical trials supported by Wellcome, MRC, CRUK and Gates Foundation. Note that CDSR is not a repository but provides a common discoverability and access portal.
Community-led activities
Wellcome are inviting the community to develop and test innovative ideas in Open Research. Some exciting initiatives include:
The Open Science Prize: this initiative was run last year in partnership with US National Institutes of Health and Howard Hughes Medical Institute. It supported prototyping and development of tools and services to build on data and content. New prizes and challenges currently being developed will build on this model.
Research Enrichment – Open Research: this was launched in November 2017. Awards of up to £50K are available for Wellcome grant-holders to develop Open Research ideas that increase the impact of their funded research.
Forthcoming: more awards and themed challenges aimed at Open Research – including a funding competition for pioneering experiments in open research, and a prize for innovative data re-use.
The Open Research Pilot Project: whereby four Wellcome-funded groups are being supported at the University of Cambridge to make their research open.
Policy Leadership
In this area, Wellcome Trust engage in policy discussions in key policy groups at the national, European and international level. They also convene international Open Research funder’s webinars. They are working towards reform on rewards and incentives for researchers, by:
Policy development and declarations
Reviewing grant assessment procedures: for example, providing guidance to staff, reviewers and panel members so that there is a more holistic approach on the value and impact of research outputs.
Engagement: for example, by being clear on how grant applicants are being evaluated and committing to celebrate grantees who are practicing Open Research.
Questions & Answers
Policy questions
I am an administrator of two Wellcome Trust programmes; how is this information about the new policy being disseminated to students? Has it been done?
When the Wellcome Open Research platform was announced last year, there was a lot of communication, for example, in grants newsletters and working with the centres.
Further dissemination of information about the updated policy on outputs management could be realised through attending events, asking questions to our teams, or inviting us to present to specific groups. In general, we are available and want to help.
Following this, the Office of Scholarly Communication added that they usually put information about things like funder policy changes in the Research Operations Office Bulletin.
Regarding your new updated policy, have you been in communication with the Government?
We work closely with HEFCE and RCUK. They are all very aware about what we aim to do.
One of the big challenges is to answer the question from researchers: “If we are not using a particular ‘big journal’ name, what are we using to help us show the quality of the research?”.
We have been working with other funders (including Research Councils) to look at issues around this. Once we have other funders on board, we need to work with institutions on staff promotion and tenure criteria. We are working with others to support a dedicated person charged with implementing the San Francisco Declaration on Research Assessment (DORA) and identify best practice.
How do you see Open Outputs going forward?
There is a growing consensus over the importance of making research outputs available, and a strong commitment from funders to overcome the challenges. Our policy is geared to openness in ways that maximise the health benefits that flow from the research we fund.
Is there a licence that you encourage researchers to use?
No. We encourage researchers to utilise existing sources of expertise (e.g. The Software Sustainability Institute) and select the licence most appropriate for them.
Some researchers could just do data collection instead of publishing papers. Will we have future where people are just generating data and publishing it on its own and not doing the analysis?
It could happen. Encouraging adoption of CRediT Taxonomy roles in publication authorship is one thing that can help.
Outputs Management Plans
How will you approach checking outputs against the outputs management plan?
We will check the information submitted at the end of grants – what outputs were reported and how these were shared – and refer back to the plan submitted at application. We will not rule out sanctions in the future once things are in place. At the moment there are no sanctions as it is premature to do this. We need to get the data first, monitor the situation and make any changes later in the process.
What are your thoughts on providing training for reviewers regarding the data management plans as well as for the people who will do the final checks? Are you going to provide any training and identify gaps on research for this?
We have provided guidance on what plans should contain; this is something we can look at going forwards.
One of the key elements to the outputs management plan is commenting on how outputs will be preserved. Does the Wellcome Trust define what it means by long term preservation anywhere?
Long term preservation is tricky. We have common best practice guidelines for data retention – 10 years for regular data and 20 years for clinical research. We encourage people to use community repositories where these exist.
What happens to the output if 10 years have passed since the last time of access?
This is a huge problem. There need to be criteria to determine what outputs are worth keeping which take into account whether the data can be regenerated. Software availability is also a consideration.
Research enrichment awards
You said that there will be prizes for data re-use, and dialogue on infrastructure is still in the early stages. What is the timeline? It would be good to push to get the timeline going worldwide.
Research enrichment awards are already live and Wellcome will assess them on an ongoing basis. Please apply if you have a Wellcome grant. Other funding opportunities will be launched in 2018. The Pioneer awards will be open to everyone in the spring and it is aimed for those who have worked out ways to make their work more FAIR. The same applies to our themed challenges for innovative data re-use which will also launch in the spring – we will identify a data set and get people to look at it. For illustration, a similar example is The NEJM SPRINT Data Analysis Challenge.
Publishing Open Access
What proportion of people are updating their articles on Wellcome Open Research?
Many people, around 15%, are editing their articles to Version 2 following review. We have one article at Version 3.
Has the Wellcome Trust any plans for overlay journals, and if so, in which repository will they be based?
Not at the moment. There will be a lot of content being published on platforms such as Open Research, the Gates platform and others. In the future, one could imagine a model where content is openly published on these platforms, and the role of journals is to identify particular articles with interesting content or high impact (rather than to manage peer review). Learned societies have the expertise in their subjects; they potentially have a role here, for example in identifying lead publications in their field from a review of the research.
Can you give us any hints about the outcome of your review of the Wellcome Trust Open Access policy? Are you going to consider not paying for hybrid journals when you review your policy?
We are about to start this review of the policy. Hybrid journals are on the agenda. We will try to simplify the process for the researcher. We are nervous about banning hybrid journals. Data from the last analysis showed that 70% of papers from Wellcome Trust grants, for which Wellcome Trust paid an article processing charge, were in hybrid journals. So if we banned hybrid journals it would not be popular. Researchers would need to know which are hybrid journals. Possibly with public health emergencies we could consider a different approach. So there is a lot to consider and a balance to keep. We will consult both researchers and institutions as part of the exercise. There is also another problem in that there is a big gap in choice between hybrid and other journals.
If researchers can publish in hybrid journals, would Wellcome Trust consider making rules regarding offsetting?
That would be interesting. However, more rules could complicate things as researchers would then also need to check both the journal’s Open Access policy and find out if they have an approved offset deal in place.
Open Data & other research outputs
What is your opinion on medical data? For example, when we write an article, we can’t publish the genetics data as there is a risk that a person could be identified.
Wellcome Trust recognise that some data cannot be made available. Our approach is to support managed access. Once the data access committee has considered that the requirement is valid, then access can be provided. The author will need to be clear on how the researcher can get hold of the data. Wellcome Trust has done work around best practice in this area.
Does Open Access mean free access? There is a cost for processing.
Yes, there is usually a cost. For some resources, those requesting data do have to pay a fee. For example, major cohort studies such as ALSPAC and UK Biobank have a fee which covers the cost of considering the request and preparing the data.
ALSPAC is developing a pilot with Wellcome Open Research to encourage those who access data and return derived datasets to the resource, to publish data papers describing data they are depositing. Because the cost of access has already been met, such data will be available at no cost.
Does the software that is used in the analysis need to be included?
Yes, the policy is that if the data is published, the software should be made available too. It is a requirement, so that everybody can reproduce the study.
Is there a limit to volume of data that can be uploaded?
Wellcome Open Research uses third party data resources (e.g. Figshare). The normal dataset limit there is 5GB, but both Figshare and subject repositories can store much higher volumes of data where required.
What can be done about misuse of data?
In the survey that we did, researchers expressed fears of data misuse. How do we address such a fear? Demonstrating the value of data will play a great role in this. It is also hard to know the extent to which these fears play out in reality – only a very small proportion of respondents indicated that they had actually experienced data being used inappropriately. We need to gather more evidence of the relative benefits and risks, and it could be argued that publishing via preprints and getting a DOI are your proofs that you got there first.
Published 26 January 2018
Written by Dr Debbie Hansen