If a tree falls in the forest and no one was there to hear it, did it happen? You could ask the same philosophical question of research – if no-one can see the research results, what was the point in the first place?
Moving science forward and increasing the knowledge of the world around implies exchange of findings. Society cannot benefit from research if there is no awareness of what has been done. Managing and sharing research data is a fundamentally important part of the research process. Yet researchers are often reluctant to share their data, and some are openly hostile to the idea.
This blog describes the research data services provided at Cambridge University which are attempting to encourage and assist researchers manage and share their data.
A tough start
The Data Management Facility project at Cambridge began operations in January 2015. At the time there was very little user support for data management in place. There was no advocacy, no training and no centralised tools to support researchers in research data management.
There had been a substantial body of work undertaken in 2010-2012 as part of the ‘Incremental’ project into research data management, but once the project money ended, the resources remained available but were not updated.
One of the initial challenges was an out of date institutional repository. Cambridge University was one of the original test-bed institutions for DSpace in 2005. While there had been considerable effort invested in the establishment of the repository, it had in recent years been somewhat neglected. The lack of both awareness of the repository and support for researchers was reflected in the numbers: during the first decade of the repository, only 72 datasets had been deposited.
In addition, the Engineering and Physical Sciences Research Council (EPSRC) had compliance expectations for funded research kicking in May 2015. This gave us five months to pull the Research Data Facility together. It was a tough start.
Understanding researchers’ needs
Tight deadlines often mean the temptation is to create short-term solutions. But we did not want to take this path. Solutions created without prior understanding of the need have no guarantee they will resolve the actual issues at hand.
So we started talking with researchers. We met and spoke with hundreds of researchers across all disciplines and fields of study – Principal Investigators, postdocs, students, and staff members. These were both group sessions and individual meetings. We told them about the importance of sharing research data, and in return we listened to what researchers told us about their worries and possible problems with data sharing.
To date, we have spoken with over 1000 researchers, and from each meeting we kept detailed notes of all the questions/comments received.
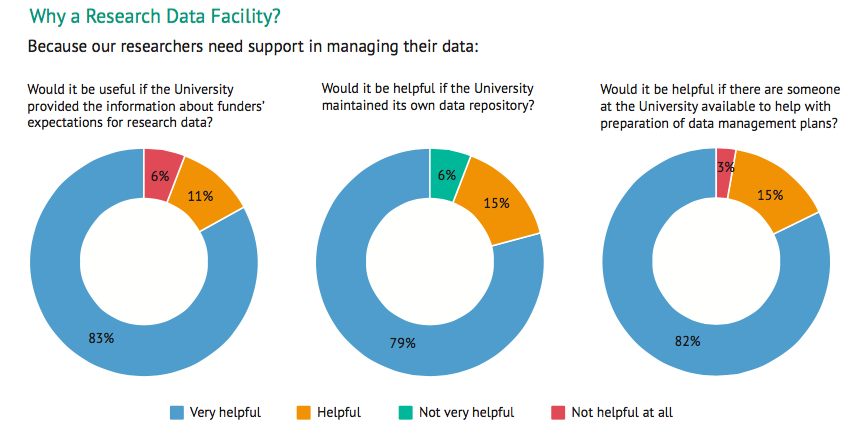
We have additionally conducted a questionnaire to better understand researchers’ needs for research data management support. Of the researchers surveyed, 83% indicated that it is ‘very useful’ for the University to provided both information about funders’ expectations for research data sharing and management, and support.
Solution 1 – Providing information
In March 2015 we launched the Research Data Management website which is a single location for solutions to all research data management needs. The website contains:
- Key information about what researchers need to know about research data management
- Summaries of and links to funder requirements for research data sharing
- Information about making data available
and much more.
The key idea behind the website is to provide an easy to navigate place with all necessary information. The website is being constantly updated, and new information is regularly added in response to feedback received from researchers.
Concurrently we have been conducting tailored information sessions about funders’ requirements for sharing data and support available at the University of Cambridge. We run these sessions at multiple locations across the University, and to audiences of various types. The sessions ranged from open sessions in central locations to dedicated sessions hosted at individual departments, and speaking with individual research groups. Slides from information sessions are always made available for attendees to download.
Solution 2 – Assistance with data management plans and supporting data management
In the survey 82% of researchers said it would be very helpful if there were someone at the University available to help with data management plans. To address this, we have:
- Added tailored information about data management plans to our information sessions.
- Linked the DMPonline tool from our data website. This allows researchers to prepare funder specific data management plans
- Organised data management plan clinic sessions (one to one appointments on demand)
- Prepared guidelines on how to fill in a data management plan.
Additionally, 63% researchers indicated that it would be ‘very useful’, and further 31% indicated that it would be ‘useful’ to have workshops on research data management. We have therefore prepared a 1.5 hour interactive introductory workshop to research data management, which is now offered across various departments across the University. We are also developing the skill sets within the library staff across the institution to deliver research data management training to researchers from their field.
Solution 3 – Providing an institutional repository
Finally, 79% of researchers indicated that it would make data sharing easier if the University maintained its own, easy to use data repository. We therefore had to do something about our repository, which had not been updated for a long time. We have rolled-out series of updates to the repository, taking it to Version 4.3, which will allow minting DOIs to datasets.
Meantime we also had to think of a strategy to make data sharing as easy as possible. The existing processes for uploading research data to the repository were very complicated and discouraging to researchers. We did not have any web-mediated facility that would allow researchers to easily get their data to us. In fact, most of the time we asked researchers to bring their data to us on external hard drives. This was not an acceptable solution in the 21st century!
Researchers like simple processes, Dropbox-like solutions, where one can easily drag and drop files. We have therefore created a simple webform, which asks researchers for the minimal necessary metadata information, and allows them to simply drag and drop their data files.
The outcomes
It turned in the end it was really worth the effort of understanding researchers’ needs before considering solutions. As of 24 August 2015, the Research Data Management website has been visited 10,992 times. Our training sessions on research data management and data planning have received extremely good feedback – 73% of respondents indicated that our workshops should be ‘essential’ to all PhD students.
And most importantly, since we launched our easy-to-upload website form for research data, we have received 122 research data submissions – in four months we have received more than 1.5 times more research outputs than in ten years of our repository’s lifetime.
So our advice to anyone wishing to really support researchers is to truly listen to their needs, and address their problems. If you create useful services, there is no need to worry about the uptake.
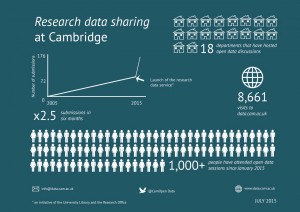 This infographic demonstrates how successful the Research Data Facility has been. Prepared by Laura Waldoch from the University Library, it is available for download.
This infographic demonstrates how successful the Research Data Facility has been. Prepared by Laura Waldoch from the University Library, it is available for download.
To know more about our activities, follow us on Twitter.
Published 24 August 2015
Written by Dr Marta Teperek and Dr Danny Kingsley
